Unsupervised Model Personalization while Preserving Privacy and Scalability: An Open Problem
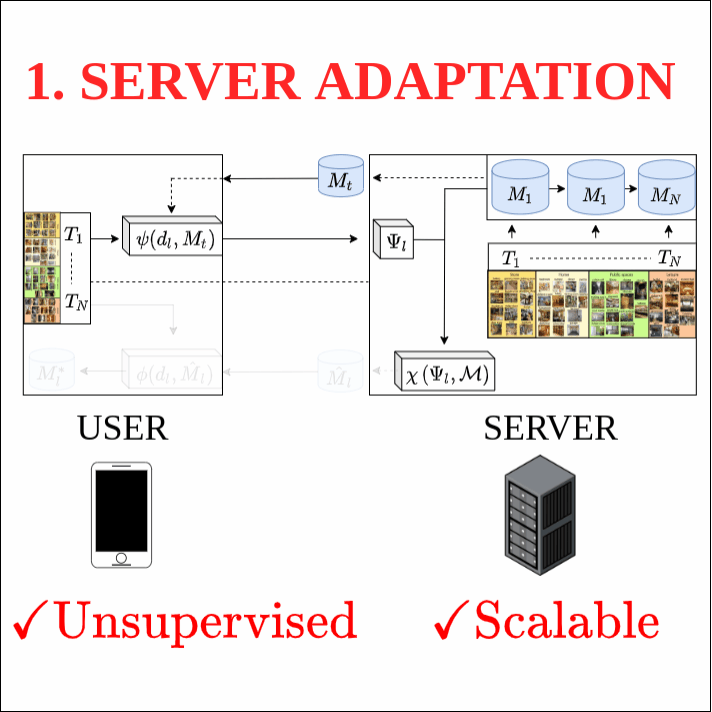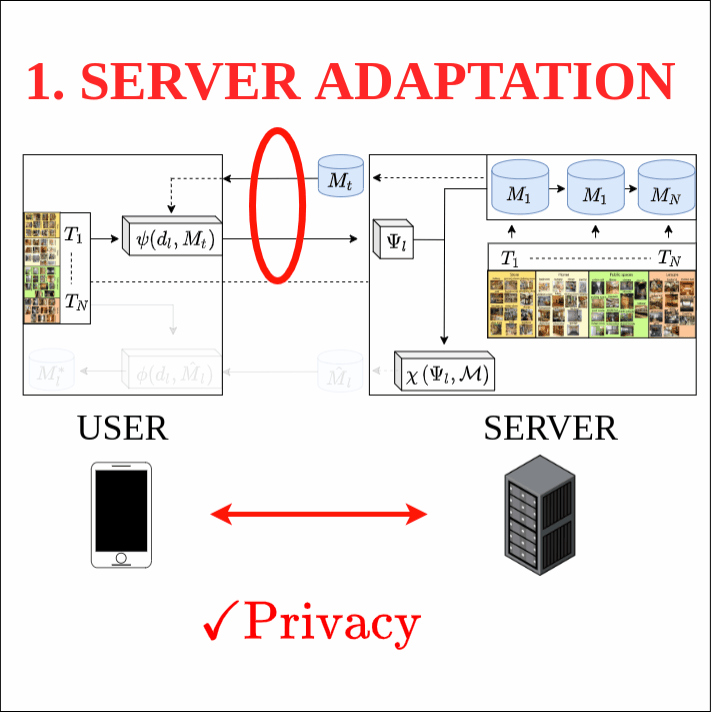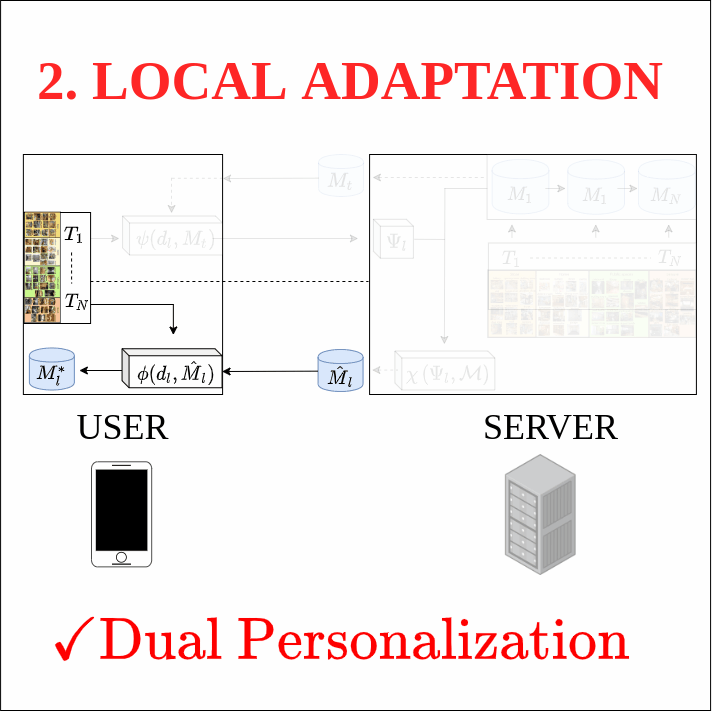
This work investigates the task of unsupervised model personalization, adapted to continually evolving, unlabeled local user images. We consider the practical scenario where a high capacity server interacts with a myriad of resource-limited edge devices, imposing strong requirements on scalability and local data privacy. We aim to address this challenge within the continual learning paradigm and provide a novel Dual User-Adaptation framework (DUA) to explore the problem. This framework flexibly disentangles user-adaptation into model personalization on the server and local data regularization on the user device, with desirable properties regarding scalability and privacy constraints. First, on the server, we introduce incremental learning of task-specific expert models, subsequently aggregated using a concealed unsupervised user prior. Aggregation avoids retraining, whereas the user prior conceals sensitive raw user data, and grants unsupervised adaptation. Second, local user-adaptation incorporates a domain adaptation point of view, adapting regularizing batch normalization parameters to the user data. We explore various empirical user configurations with different priors in categories and a tenfold of transforms for MIT Indoor Scene recognition, and classify numbers in a combined MNIST and SVHN setup. Extensive experiments yield promising results for data-driven local adaptation and elicit user priors for server adaptation to depend on the model rather than user data. Hence, although user-adaptation remains a challenging open problem, the DUA framework formalizes a principled foundation for personalizing both on server and user device, while maintaining privacy and scalability.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract




 SVHN
SVHN
