End-to-End Speech Translation with Pre-trained Models and Adapters: UPC at IWSLT 2021
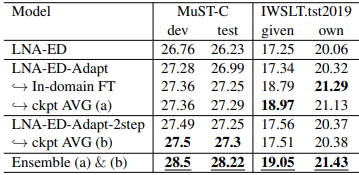
This paper describes the submission to the IWSLT 2021 offline speech translation task by the UPC Machine Translation group. The task consists of building a system capable of translating English audio recordings extracted from TED talks into German text. Submitted systems can be either cascade or end-to-end and use a custom or given segmentation. Our submission is an end-to-end speech translation system, which combines pre-trained models (Wav2Vec 2.0 and mBART) with coupling modules between the encoder and decoder, and uses an efficient fine-tuning technique, which trains only 20% of its total parameters. We show that adding an Adapter to the system and pre-training it, can increase the convergence speed and the final result, with which we achieve a BLEU score of 27.3 on the MuST-C test set. Our final model is an ensemble that obtains 28.22 BLEU score on the same set. Our submission also uses a custom segmentation algorithm that employs pre-trained Wav2Vec 2.0 for identifying periods of untranscribable text and can bring improvements of 2.5 to 3 BLEU score on the IWSLT 2019 test set, as compared to the result with the given segmentation.
PDF Abstract ACL (IWSLT) 2021 PDF ACL (IWSLT) 2021 Abstract

Datasets
 MuST-C
MuST-C
Results from the Paper
![]() Ranked #2 on
Speech-to-Text Translation
on MuST-C EN->DE
(using extra training data)
Ranked #2 on
Speech-to-Text Translation
on MuST-C EN->DE
(using extra training data)
| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Speech-to-Text Translation | MuST-C EN->DE | Wav2Vec2.0+mBART+Adaptors | Case-sensitive sacreBLEU | 28.22 | # 2 |
