Video Relationship Reasoning using Gated Spatio-Temporal Energy Graph
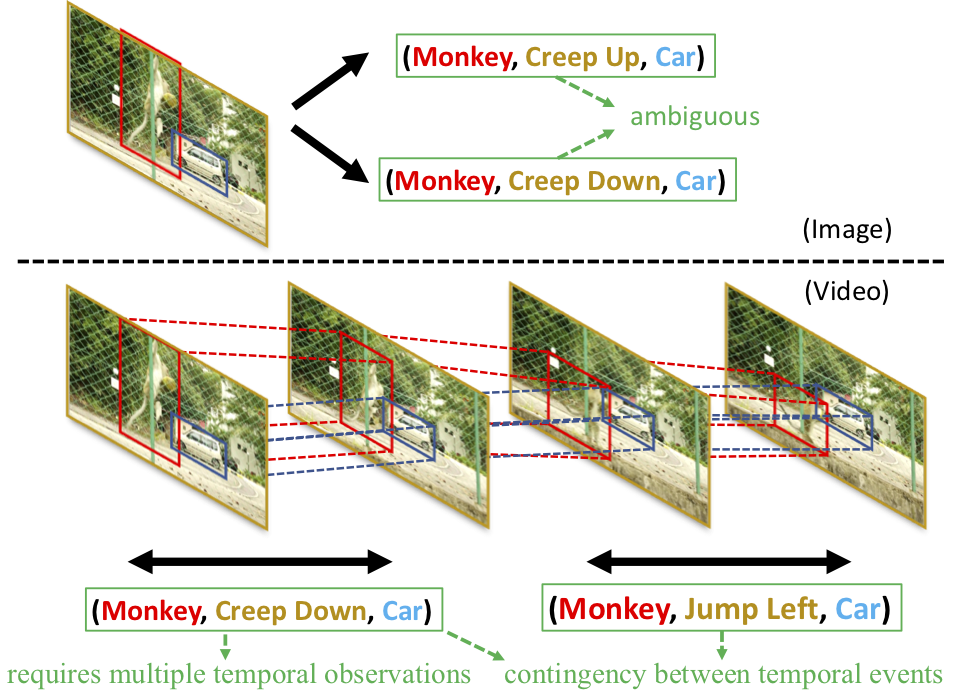
Visual relationship reasoning is a crucial yet challenging task for understanding rich interactions across visual concepts. For example, a relationship 'man, open, door' involves a complex relation 'open' between concrete entities 'man, door'. While much of the existing work has studied this problem in the context of still images, understanding visual relationships in videos has received limited attention. Due to their temporal nature, videos enable us to model and reason about a more comprehensive set of visual relationships, such as those requiring multiple (temporal) observations (e.g., 'man, lift up, box' vs. 'man, put down, box'), as well as relationships that are often correlated through time (e.g., 'woman, pay, money' followed by 'woman, buy, coffee'). In this paper, we construct a Conditional Random Field on a fully-connected spatio-temporal graph that exploits the statistical dependency between relational entities spatially and temporally. We introduce a novel gated energy function parametrization that learns adaptive relations conditioned on visual observations. Our model optimization is computationally efficient, and its space computation complexity is significantly amortized through our proposed parameterization. Experimental results on benchmark video datasets (ImageNet Video and Charades) demonstrate state-of-the-art performance across three standard relationship reasoning tasks: Detection, Tagging, and Recognition.
PDF Abstract CVPR 2019 PDF CVPR 2019 Abstract


 VRD
VRD
