Voice2Mesh: Cross-Modal 3D Face Model Generation from Voices
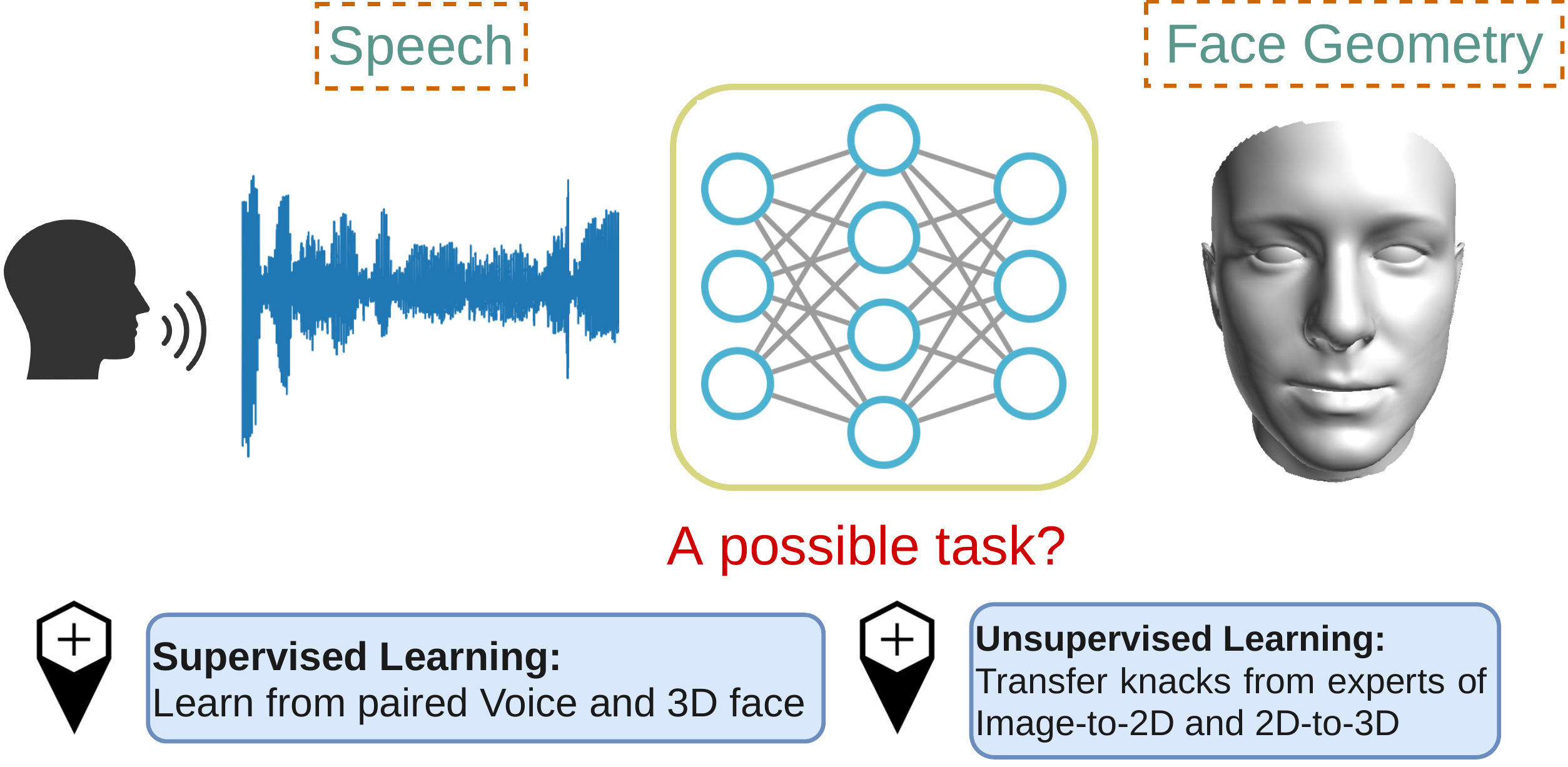
This work focuses on the analysis that whether 3D face models can be learned from only the speech inputs of speakers. Previous works for cross-modal face synthesis study image generation from voices. However, image synthesis includes variations such as hairstyles, backgrounds, and facial textures, that are arguably irrelevant to voice or without direct studies to show correlations. We instead investigate the ability to reconstruct 3D faces to concentrate on only geometry, which is more physiologically grounded. We propose both the supervised learning and unsupervised learning frameworks. Especially we demonstrate how unsupervised learning is possible in the absence of a direct voice-to-3D-face dataset under limited availability of 3D face scans when the model is equipped with knowledge distillation. To evaluate the performance, we also propose several metrics to measure the geometric fitness of two 3D faces based on points, lines, and regions. We find that 3D face shapes can be reconstructed from voices. Experimental results suggest that 3D faces can be reconstructed from voices, and our method can improve the performance over the baseline. The best performance gains (15% - 20%) on ear-to-ear distance ratio metric (ER) coincides with the intuition that one can roughly envision whether a speaker's face is overall wider or thinner only from a person's voice. See our project page for codes and data.
PDF Abstract



 VoxCeleb1
VoxCeleb1
