WavJourney: Compositional Audio Creation with Large Language Models
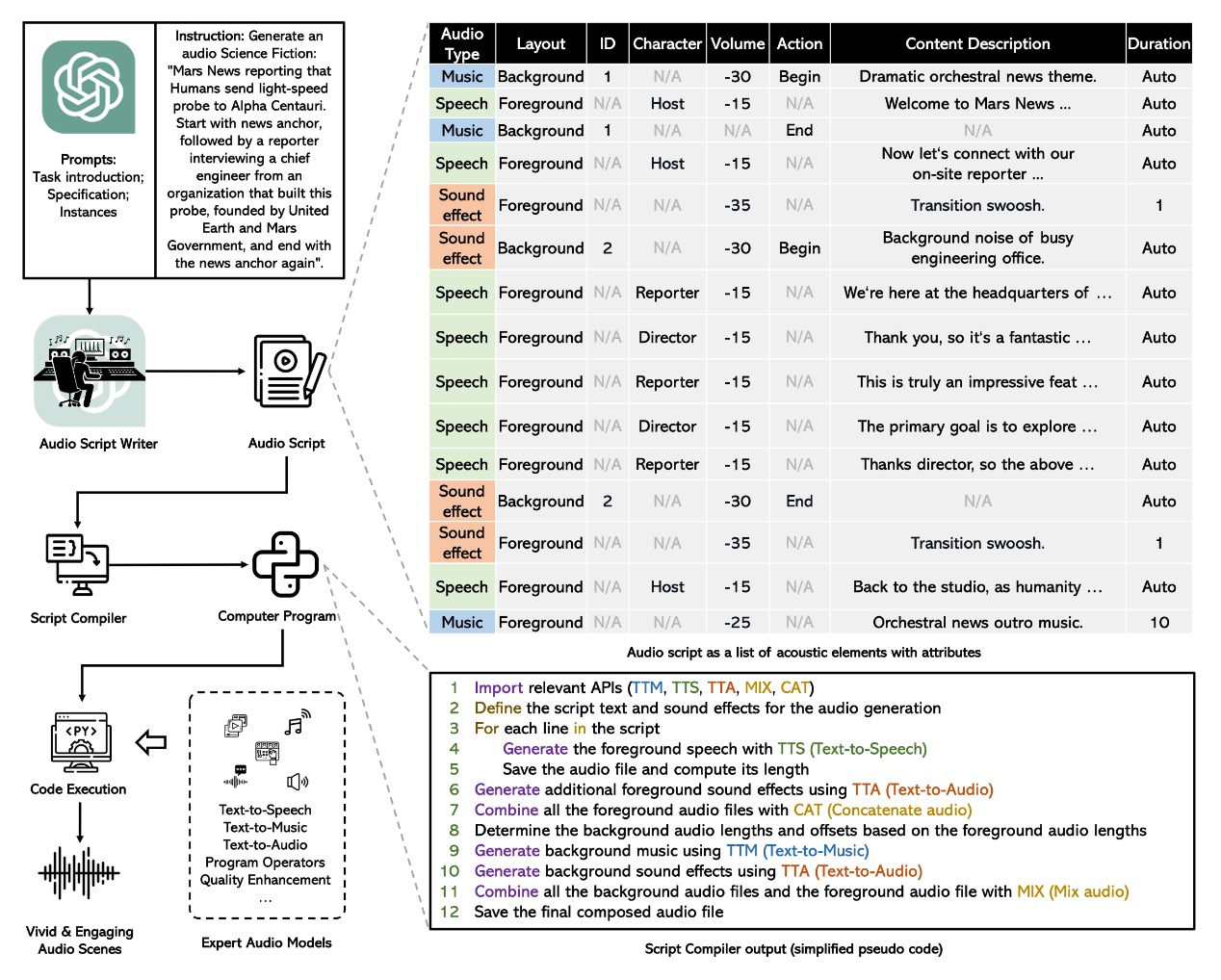
Despite breakthroughs in audio generation models, their capabilities are often confined to domain-specific conditions such as speech transcriptions and audio captions. However, real-world audio creation aims to generate harmonious audio containing various elements such as speech, music, and sound effects with controllable conditions, which is challenging to address using existing audio generation systems. We present WavJourney, a novel framework that leverages Large Language Models (LLMs) to connect various audio models for audio creation. WavJourney allows users to create storytelling audio content with diverse audio elements simply from textual descriptions. Specifically, given a text instruction, WavJourney first prompts LLMs to generate an audio script that serves as a structured semantic representation of audio elements. The audio script is then converted into a computer program, where each line of the program calls a task-specific audio generation model or computational operation function. The computer program is then executed to obtain a compositional and interpretable solution for audio creation. Experimental results suggest that WavJourney is capable of synthesizing realistic audio aligned with textually-described semantic, spatial and temporal conditions, achieving state-of-the-art results on text-to-audio generation benchmarks. Additionally, we introduce a new multi-genre story benchmark. Subjective evaluations demonstrate the potential of WavJourney in crafting engaging storytelling audio content from text. We further demonstrate that WavJourney can facilitate human-machine co-creation in multi-round dialogues. To foster future research, the code and synthesized audio are available at: https://audio-agi.github.io/WavJourney_demopage/.
PDF Abstract Spaces
Spaces


 AudioCaps
AudioCaps
 Clotho
Clotho
