Where Visual Speech Meets Language: VSP-LLM Framework for Efficient and Context-Aware Visual Speech Processing
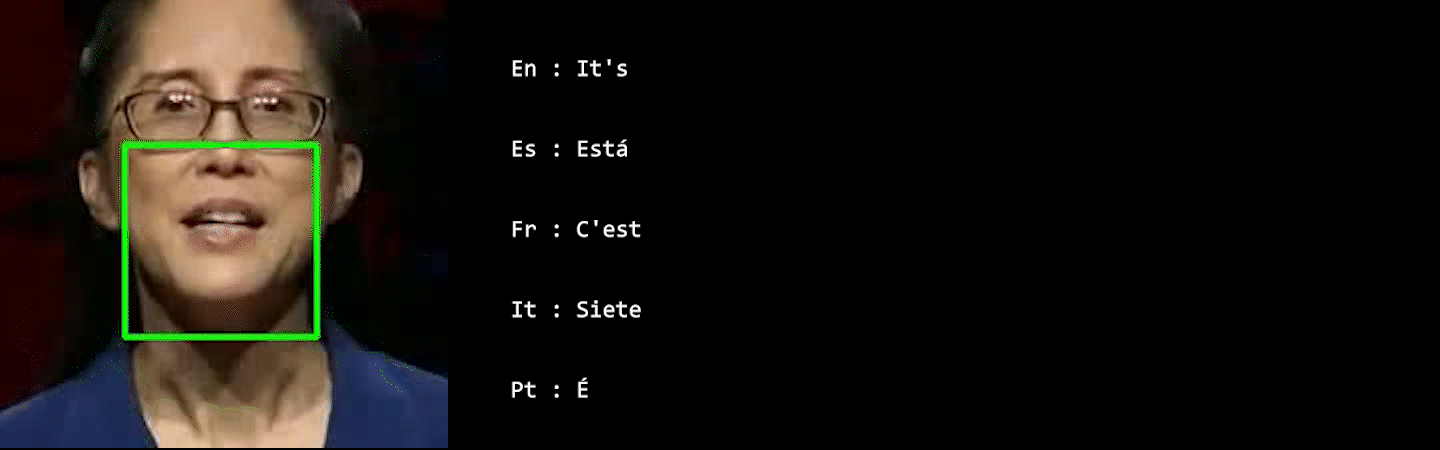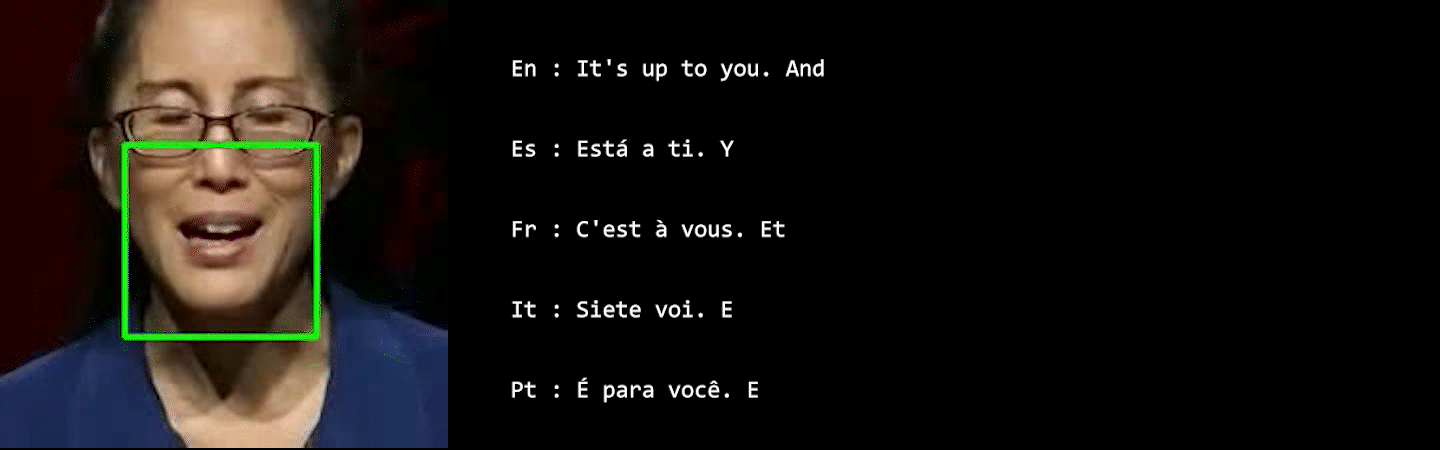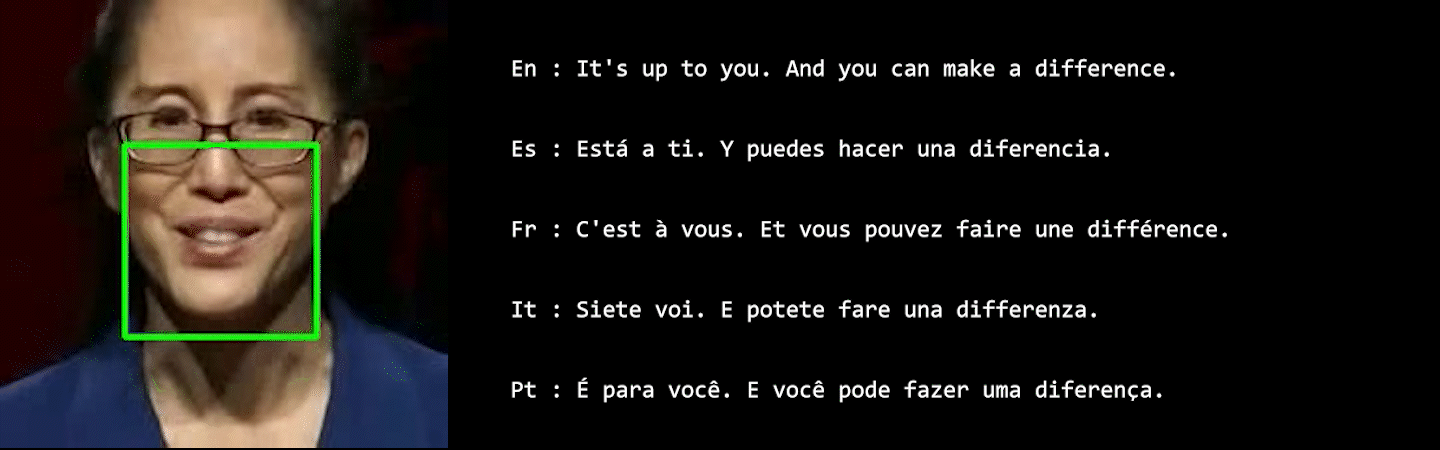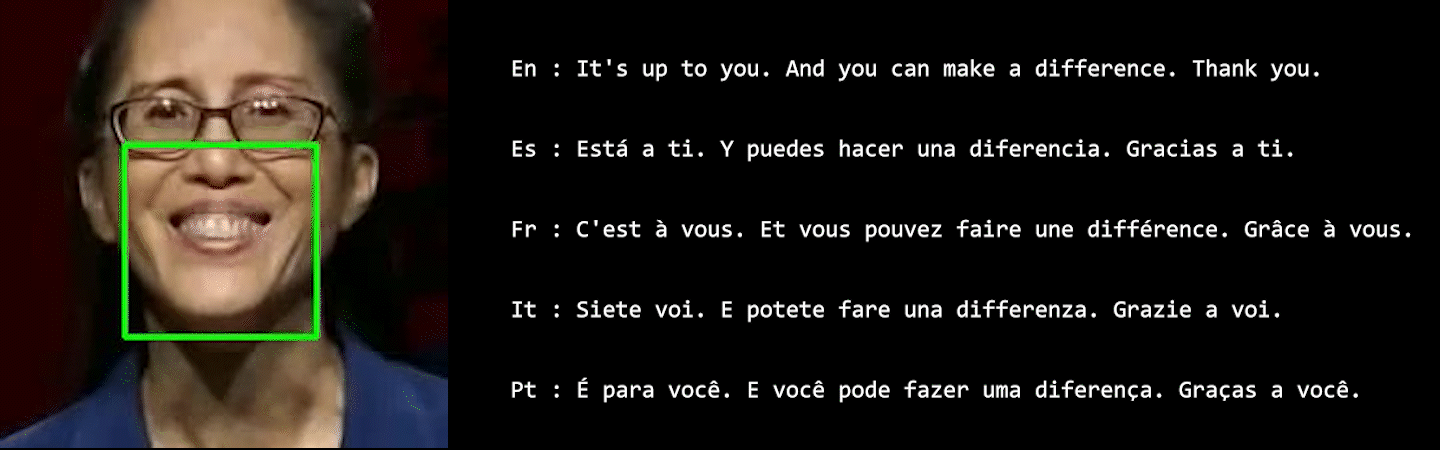
In visual speech processing, context modeling capability is one of the most important requirements due to the ambiguous nature of lip movements. For example, homophenes, words that share identical lip movements but produce different sounds, can be distinguished by considering the context. In this paper, we propose a novel framework, namely Visual Speech Processing incorporated with LLMs (VSP-LLM), to maximize the context modeling ability by bringing the overwhelming power of LLMs. Specifically, VSP-LLM is designed to perform multi-tasks of visual speech recognition and translation, where the given instructions control the type of task. The input video is mapped to the input latent space of a LLM by employing a self-supervised visual speech model. Focused on the fact that there is redundant information in input frames, we propose a novel deduplication method that reduces the embedded visual features by employing visual speech units. Through the proposed deduplication and Low Rank Adaptors (LoRA), VSP-LLM can be trained in a computationally efficient manner. In the translation dataset, the MuAViC benchmark, we demonstrate that VSP-LLM can more effectively recognize and translate lip movements with just 15 hours of labeled data, compared to the recent translation model trained with 433 hours of labeld data.
PDF AbstractCode



Datasets
Results from the Paper
 Ranked #4 on
Lipreading
on LRS3-TED
(using extra training data)
Ranked #4 on
Lipreading
on LRS3-TED
(using extra training data)
| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Lipreading | LRS3-TED | VSP-LLM | Word Error Rate (WER) | 26.9 | # 4 |
