Writer-Aware CNN for Parsimonious HMM-Based Offline Handwritten Chinese Text Recognition
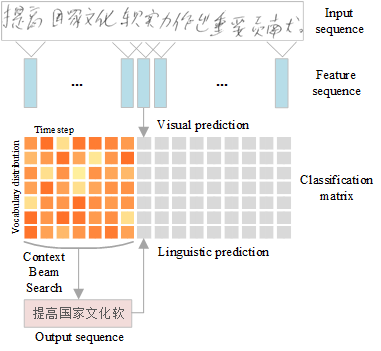
Recently, the hybrid convolutional neural network hidden Markov model (CNN-HMM) has been introduced for offline handwritten Chinese text recognition (HCTR) and has achieved state-of-the-art performance. However, modeling each of the large vocabulary of Chinese characters with a uniform and fixed number of hidden states requires high memory and computational costs and makes the tens of thousands of HMM state classes confusing. Another key issue of CNN-HMM for HCTR is the diversified writing style, which leads to model strain and a significant performance decline for specific writers. To address these issues, we propose a writer-aware CNN based on parsimonious HMM (WCNN-PHMM). First, PHMM is designed using a data-driven state-tying algorithm to greatly reduce the total number of HMM states, which not only yields a compact CNN by state sharing of the same or similar radicals among different Chinese characters but also improves the recognition accuracy due to the more accurate modeling of tied states and the lower confusion among them. Second, WCNN integrates each convolutional layer with one adaptive layer fed by a writer-dependent vector, namely, the writer code, to extract the irrelevant variability in writer information to improve recognition performance. The parameters of writer-adaptive layers are jointly optimized with other network parameters in the training stage, while a multiple-pass decoding strategy is adopted to learn the writer code and generate recognition results. Validated on the ICDAR 2013 competition of CASIA-HWDB database, the more compact WCNN-PHMM of a 7360-class vocabulary can achieve a relative character error rate (CER) reduction of 16.6% over the conventional CNN-HMM without considering language modeling. By adopting a powerful hybrid language model (N-gram language model and recurrent neural network language model), the CER of WCNN-PHMM is reduced to 3.17%.
PDF Abstract


 CASIA-HWDB
CASIA-HWDB
