Zemi: Learning Zero-Shot Semi-Parametric Language Models from Multiple Tasks
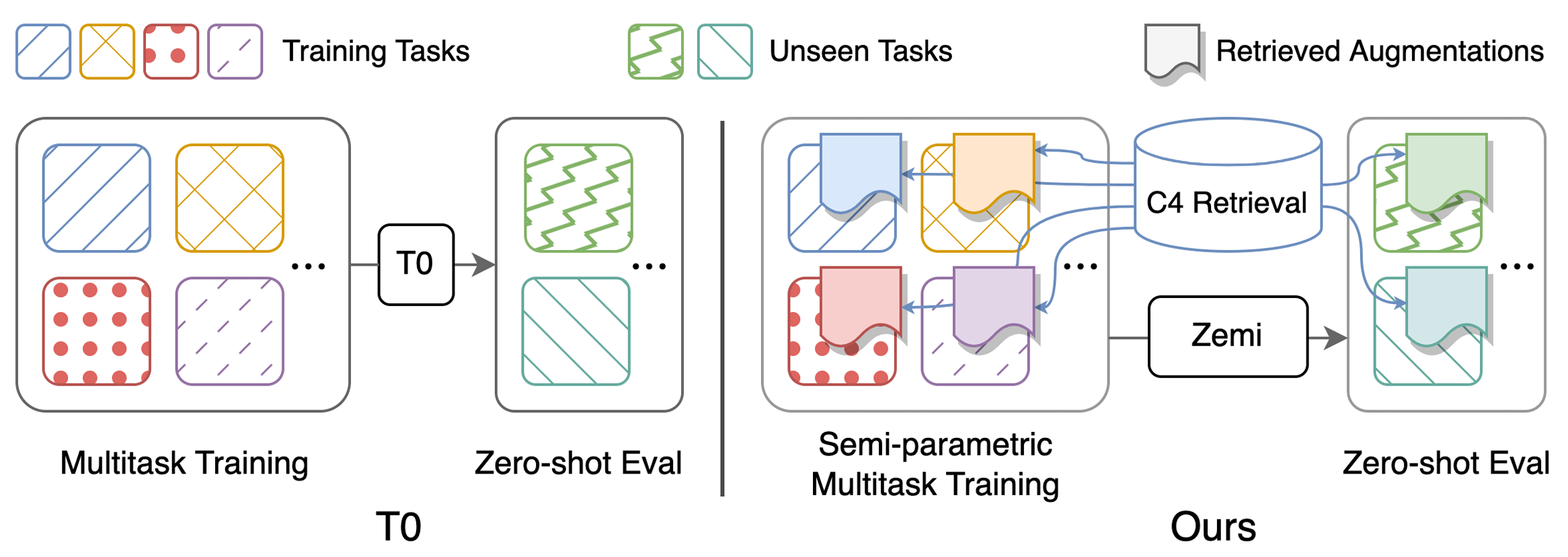
Although large language models have achieved impressive zero-shot ability, the huge model size generally incurs high cost. Recently, semi-parametric language models, which augment a smaller language model with an external retriever, have demonstrated promising language modeling capabilities. However, it remains unclear whether such semi-parametric language models can perform competitively well as their fully-parametric counterparts on zero-shot generalization to downstream tasks. In this work, we introduce $\text{Zemi}$, a zero-shot semi-parametric language model. To our best knowledge, this is the first semi-parametric language model that can demonstrate strong zero-shot performance on a wide range of held-out unseen tasks. We train $\text{Zemi}$ with a novel semi-parametric multitask prompted training paradigm, which shows significant improvement compared with the parametric multitask training as proposed by T0. Specifically, we augment the multitask training and zero-shot evaluation with retrieval from a large-scale task-agnostic unlabeled corpus. In order to incorporate multiple potentially noisy retrieved augmentations, we further propose a novel $\text{augmentation fusion}$ module leveraging perceiver resampler and gated cross-attention. Notably, our proposed $\text{Zemi}_\text{LARGE}$ outperforms T0-3B by 16% on all seven evaluation tasks while being 3.9x smaller in model size.
PDF Abstract



 C4
C4
 PIQA
PIQA
 OpenBookQA
OpenBookQA
 COPA
COPA
