DEEP-VOICE: DeepFake Voice Recognition (Jordan Bird)

DEEP-VOICE: Real-time Detection of AI-Generated Speech for DeepFake Voice Conversion
This dataset contains examples of real human speech, and DeepFake versions of those speeches by using Retrieval-based Voice Conversion.
Can machine learning be used to detect when speech is AI-generated?
Introduction
There are growing implications surrounding generative AI in the speech domain that enable voice cloning and real-time voice conversion from one individual to another. This technology poses a significant ethical threat and could lead to breaches of privacy and misrepresentation, thus there is an urgent need for real-time detection of AI-generated speech for DeepFake Voice Conversion.
To address the above emerging issues, we are introducing the DEEP-VOICE dataset. DEEP-VOICE is comprised of real human speech from eight well-known figures and their speech converted to one another using Retrieval-based Voice Conversion.
For each speech, the accompaniment ("background noise") was removed before conversion using RVC. The original accompaniment is then added back to the DeepFake speech:
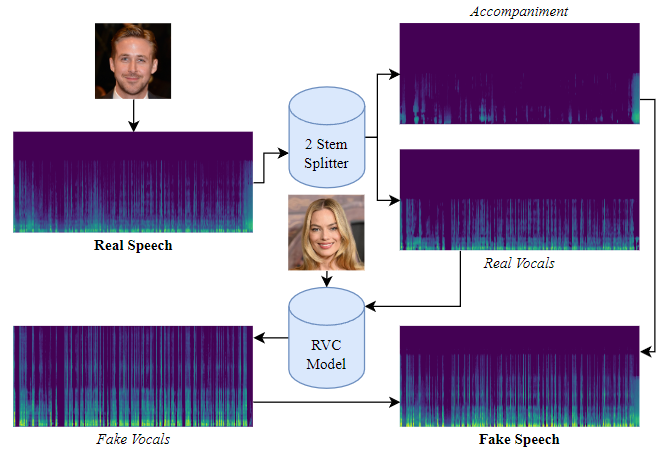
(Above: Overview of the Retrieval-based Voice Conversion process to generate DeepFake speech with Ryan Gosling's speech converted to Margot Robbie. Conversion is run on the extracted vocals before being layered on the original background ambience.)
Dataset
There are two forms to the dataset that are made available.
First, the raw audio can be found in the "AUDIO" directory. They are arranged within "REAL" and "FAKE" class directories. The audio filenames note which speakers provided the real speech, and which voices they were converted to. For example "Obama-to-Biden" denotes that Barack Obama's speech has been converted to Joe Biden's voice.
Second, the extracted features can be found in the "DATASET-balanced.csv" file. This is the data that was used in the below study. The dataset has each feature extracted from one-second windows of audio and are balanced through random sampling.
Note: All experimental data is found within the "KAGGLE" directory. The "DEMONSTRATION" directory is used for playing cropped and compressed demos in notebooks due to Kaggle's limitations on file size.
A potential use of a successful system could be used for the following:
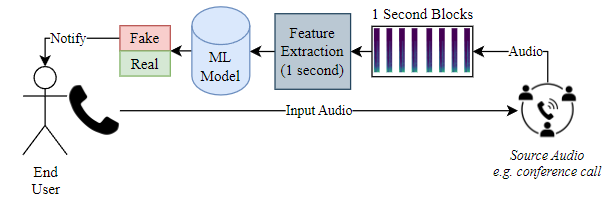
(Above: Usage of the real-time system. The end user is notified when the machine learning model has processed the speech audio (e.g. a phone or conference call) and predicted that audio chunks contain AI-generated speech.)
Kaggle
The dataset is available on the Kaggle data science platform.
The Kaggle page can be found by clicking here: Dataset on Kaggle
Attribution
This dataset was produced from the study "Real-time Detection of AI-Generated Speech for DeepFake Voice Conversion"
The preprint can be found on ArXiv by clicking here: Real-time Detection of AI-Generated Speech for DeepFake Voice Conversion
License
This dataset is provided under the MIT License:
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Benchmarks
| Trend | Task | Dataset Variant | Best Model | Paper | Code |
|---|---|---|---|---|---|

|
DEEP-VOICE: DeepFake Voice Recognition
|
XGBoost
|
Papers
| Paper | Code | Results | Date | Stars |
|---|



