TabFact
Introduced by Chen et al. in TabFact: A Large-scale Dataset for Table-based Fact Verification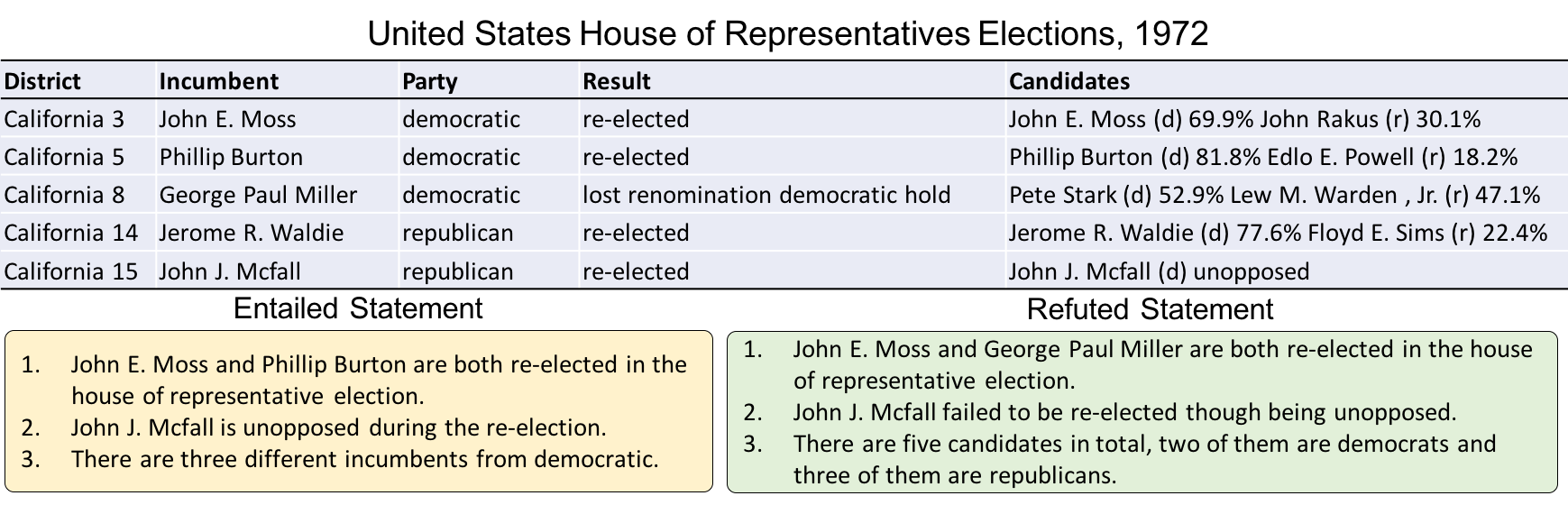
TabFact is a large-scale dataset which consists of 117,854 manually annotated statements with regard to 16,573 Wikipedia tables, their relations are classified as ENTAILED and REFUTED. TabFact is the first dataset to evaluate language inference on structured data, which involves mixed reasoning skills in both symbolic and linguistic aspects.
Source: GitHubBenchmarks
| Trend | Task | Dataset Variant | Best Model | Paper | Code |
|---|---|---|---|---|---|

|
TabFact
|
Dater
|
Papers
| Paper | Code | Results | Date | Stars |
|---|





