 Vision Transformers
Vision Transformers
DeepViT
Introduced by Zhou et al. in DeepViT: Towards Deeper Vision TransformerDeepViT is a type of vision transformer that replaces the self-attention layer within the transformer block with a Re-attention module to address the issue of attention collapse and enables training deeper ViTs.
Source: DeepViT: Towards Deeper Vision Transformer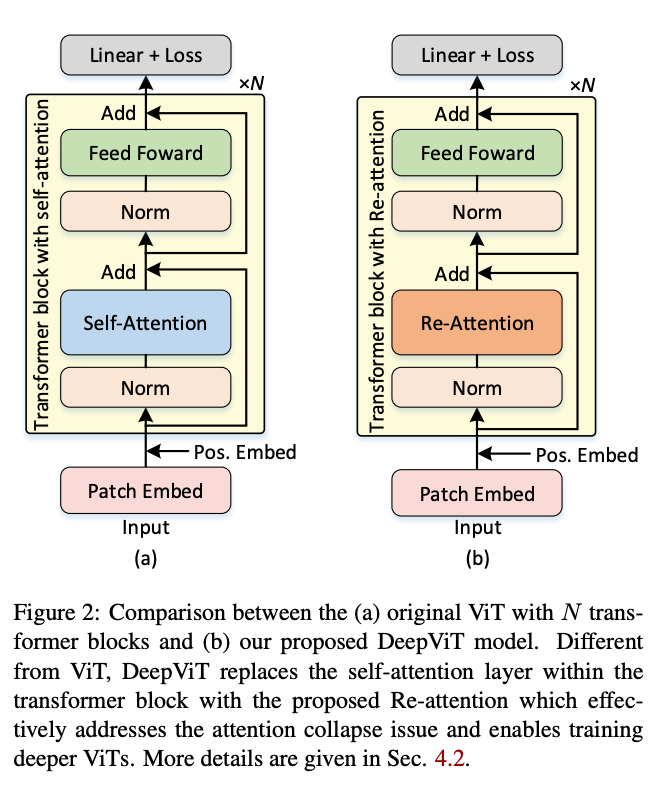
Papers
| Paper | Code | Results | Date | Stars |
|---|
 Re-Attention Module
Re-Attention Module

