 Attention Mechanisms
Attention Mechanisms
Fast Attention Via Positive Orthogonal Random Features
Introduced by Choromanski et al. in Rethinking Attention with PerformersFAVOR+, or Fast Attention Via Positive Orthogonal Random Features, is an efficient attention mechanism used in the Performer architecture which leverages approaches such as kernel methods and random features approximation for approximating softmax and Gaussian kernels.
FAVOR+ works for attention blocks using matrices $\mathbf{A} \in \mathbb{R}^{L×L}$ of the form $\mathbf{A}(i, j) = K(\mathbf{q}_{i}^{T}, \mathbf{k}_{j}^{T})$, with $\mathbf{q}_{i}/\mathbf{k}_{j}$ standing for the $i^{th}/j^{th}$ query/key row-vector in $\mathbf{Q}/\mathbf{K}$ and kernel $K : \mathbb{R}^{d } × \mathbb{R}^{d} \rightarrow \mathbb{R}_{+}$ defined for the (usually randomized) mapping: $\phi : \mathbb{R}^{d } → \mathbb{R}^{r}_{+}$ (for some $r > 0$) as:
$$K(\mathbf{x}, \mathbf{y}) = E[\phi(\mathbf{x})^{T}\phi(\mathbf{y})] $$
We call $\phi(\mathbf{u})$ a random feature map for $\mathbf{u} \in \mathbb{R}^{d}$ . For $\mathbf{Q}^{'}, \mathbf{K}^{'} \in \mathbb{R}^{L \times r}$ with rows given as $\phi(\mathbf{q}_{i}^{T})^{T}$ and $\phi(\mathbf{k}_{i}^{T})^{T}$ respectively, this leads directly to the efficient attention mechanism of the form:
$$ \hat{Att_{\leftrightarrow}}\left(\mathbf{Q}, \mathbf{K}, \mathbf{V}\right) = \hat{\mathbf{D}}^{-1}(\mathbf{Q^{'}}((\mathbf{K^{'}})^{T}\mathbf{V}))$$
where
$$\mathbf{\hat{D}} = \text{diag}(\mathbf{Q^{'}}((\mathbf{K^{'}})\mathbf{1}_{L})) $$
The above scheme constitutes the FA-part of the FAVOR+ mechanism. The other parts are achieved by:
- The R part : The softmax kernel is approximated though trigonometric functions, in the form of a regularized softmax-kernel SMREG, that employs positive random features (PRFs).
- The OR+ part : To reduce the variance of the estimator, so we can use a smaller number of random features, different samples are entangled to be exactly orthogonal using the Gram-Schmidt orthogonalization procedure.
The details are quite technical, so it is recommended you read the paper for further information on these steps.
Source: Rethinking Attention with Performers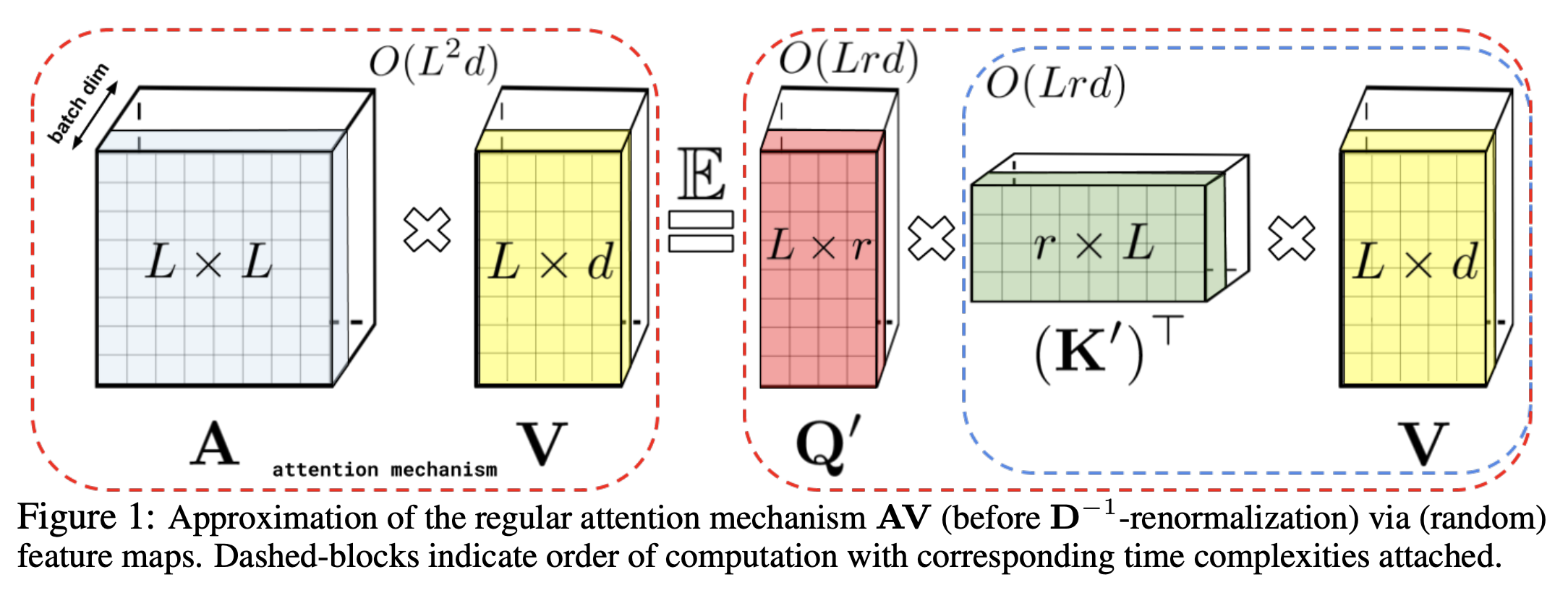
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Language Modelling | 5 | 5.68% |
| Time Series Analysis | 4 | 4.55% |
| Image Classification | 3 | 3.41% |
| Novel View Synthesis | 3 | 3.41% |
| Classification | 3 | 3.41% |
| Anomaly Detection | 2 | 2.27% |
| Dynamic Time Warping | 2 | 2.27% |
| Image Generation | 2 | 2.27% |
| Time Series Anomaly Detection | 2 | 2.27% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
