 Generative Audio Models
Generative Audio Models
MelGAN
Introduced by Kumar et al. in MelGAN: Generative Adversarial Networks for Conditional Waveform SynthesisMelGAN is a non-autoregressive feed-forward convolutional architecture to perform audio waveform generation in a GAN setup. The architecture is a fully convolutional feed-forward network with mel-spectrogram $s$ as input and raw waveform $x$ as output. Since the mel-spectrogram is at a 256× lower temporal resolution, the authors use a stack of transposed convolutional layers to upsample the input sequence. Each transposed convolutional layer is followed by a stack of residual blocks with dilated convolutions. Unlike traditional GANs, the MelGAN generator does not use a global noise vector as input.
To deal with 'checkerboard artifacts' in audio, instead of using PhaseShuffle, MelGAN uses kernel-size as a multiple of stride.
Weight normalization is used for normalization. A window-based discriminator, similar to a PatchGAN is used for the discriminator.
Source: MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis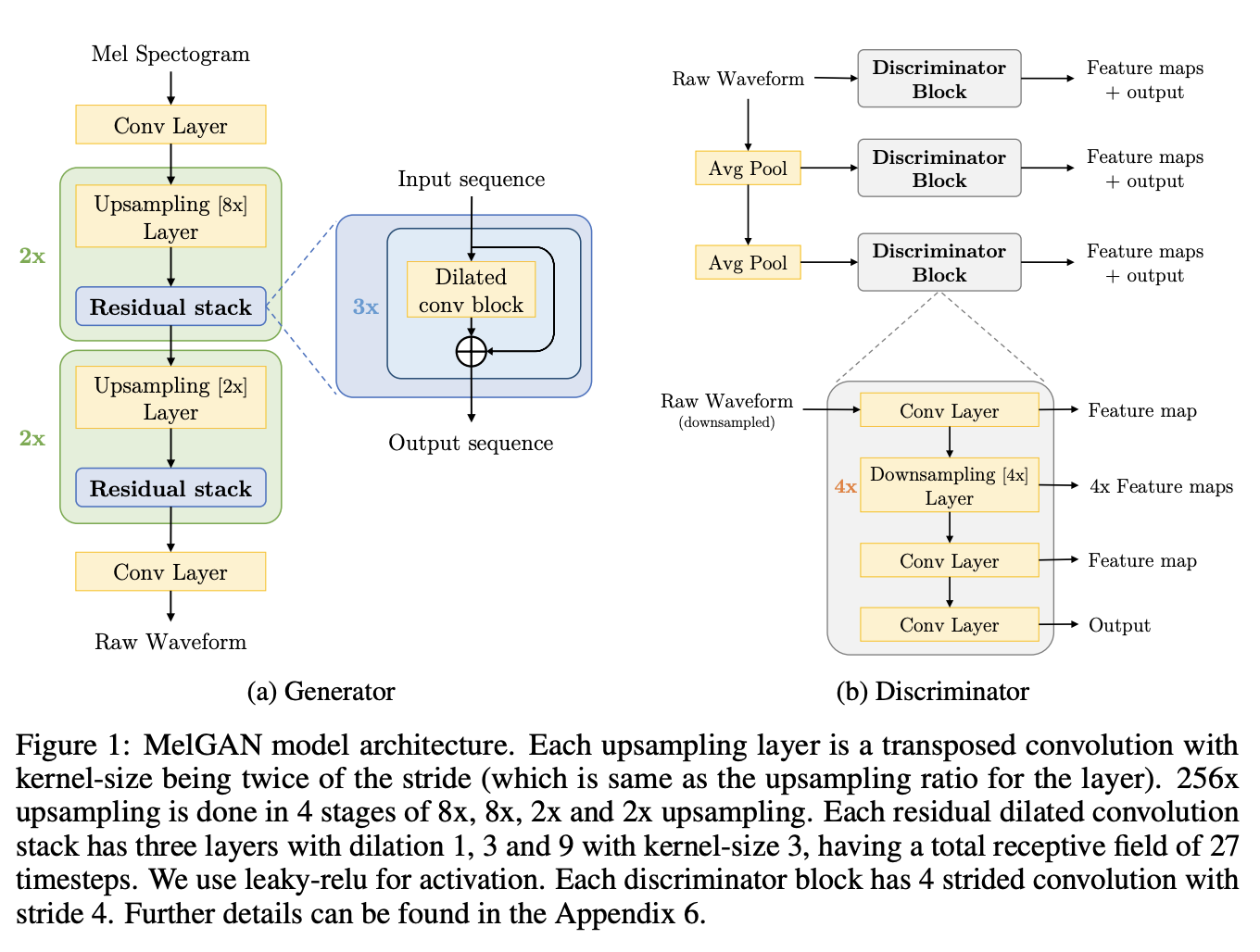
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Speech Synthesis | 7 | 53.85% |
| BIG-bench Machine Learning | 1 | 7.69% |
| Music Generation | 1 | 7.69% |
| Face Swapping | 1 | 7.69% |
| Spectral Reconstruction | 1 | 7.69% |
| Speech Enhancement | 1 | 7.69% |
| Translation | 1 | 7.69% |
 Average Pooling
Average Pooling
 Convolution
Convolution
 GAN Feature Matching
GAN Feature Matching
 GAN Hinge Loss
GAN Hinge Loss
 Leaky ReLU
Leaky ReLU
 MelGAN Residual Block
MelGAN Residual Block
 Tanh Activation
Tanh Activation
 Weight Normalization
Weight Normalization
 Window-based Discriminator
Window-based Discriminator
