 Working Memory Models
Working Memory Models
Memory Network
Introduced by Weston et al. in Memory NetworksA Memory Network provides a memory component that can be read from and written to with the inference capabilities of a neural network model. The motivation is that many neural networks lack a long-term memory component, and their existing memory component encoded by states and weights is too small and not compartmentalized enough to accurately remember facts from the past (RNNs for example, have difficult memorizing and doing tasks like copying).
A memory network consists of a memory $\textbf{m}$ (an array of objects indexed by $\textbf{m}_{i}$ and four potentially learned components:
- Input feature map $I$ - feature representation of the data input.
- Generalization $G$ - updates old memories given the new input.
- Output feature map $O$ - produces new feature map given $I$ and $G$.
- Response $R$ - converts output into the desired response.
Given an input $x$ (e.g., an input character, word or sentence depending on the granularity chosen, an image or an audio signal) the flow of the model is as follows:
- Convert $x$ to an internal feature representation $I\left(x\right)$.
- Update memories $m_{i}$ given the new input: $m_{i} = G\left(m_{i}, I\left(x\right), m\right)$, $\forall{i}$.
- Compute output features $o$ given the new input and the memory: $o = O\left(I\left(x\right), m\right)$.
- Finally, decode output features $o$ to give the final response: $r = R\left(o\right)$.
This process is applied at both train and test time, if there is a distinction between such phases, that is, memories are also stored at test time, but the model parameters of $I$, $G$, $O$ and $R$ are not updated. Memory networks cover a wide class of possible implementations. The components $I$, $G$, $O$ and $R$ can potentially use any existing ideas from the machine learning literature.
Image Source: Adrian Colyer
Source: Memory Networks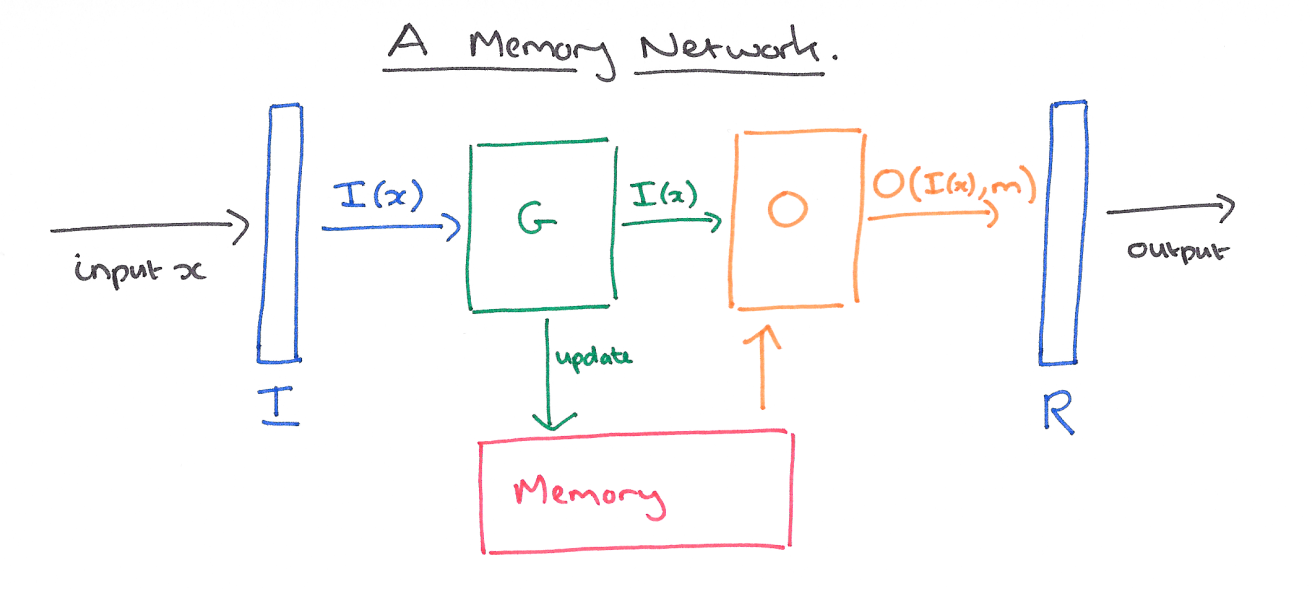
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Question Answering | 35 | 4.69% |
| General Classification | 26 | 3.48% |
| Semantic Segmentation | 24 | 3.21% |
| Time Series Analysis | 23 | 3.08% |
| Sentence | 20 | 2.68% |
| Video Semantic Segmentation | 19 | 2.54% |
| Video Object Segmentation | 17 | 2.28% |
| Language Modelling | 16 | 2.14% |
| Classification | 16 | 2.14% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
