 Working Memory Models
Working Memory Models
Neural Turing Machine
Introduced by Graves et al. in Neural Turing MachinesA Neural Turing Machine is a working memory neural network model. It couples a neural network architecture with external memory resources. The whole architecture is differentiable end-to-end with gradient descent. The models can infer tasks such as copying, sorting and associative recall.
A Neural Turing Machine (NTM) architecture contains two basic components: a neural network controller and a memory bank. The Figure presents a high-level diagram of the NTM architecture. Like most neural networks, the controller interacts with the external world via input and output vectors. Unlike a standard network, it also interacts with a memory matrix using selective read and write operations. By analogy to the Turing machine we refer to the network outputs that parameterise these operations as “heads.”
Every component of the architecture is differentiable. This is achieved by defining 'blurry' read and write operations that interact to a greater or lesser degree with all the elements in memory (rather than addressing a single element, as in a normal Turing machine or digital computer). The degree of blurriness is determined by an attentional “focus” mechanism that constrains each read and write operation to interact with a small portion of the memory, while ignoring the rest. Because interaction with the memory is highly sparse, the NTM is biased towards storing data without interference. The memory location brought into attentional focus is determined by specialised outputs emitted by the heads. These outputs define a normalised weighting over the rows in the memory matrix (referred to as memory “locations”). Each weighting, one per read or write head, defines the degree to which the head reads or writes at each location. A head can thereby attend sharply to the memory at a single location or weakly to the memory at many locations
Source: Neural Turing Machines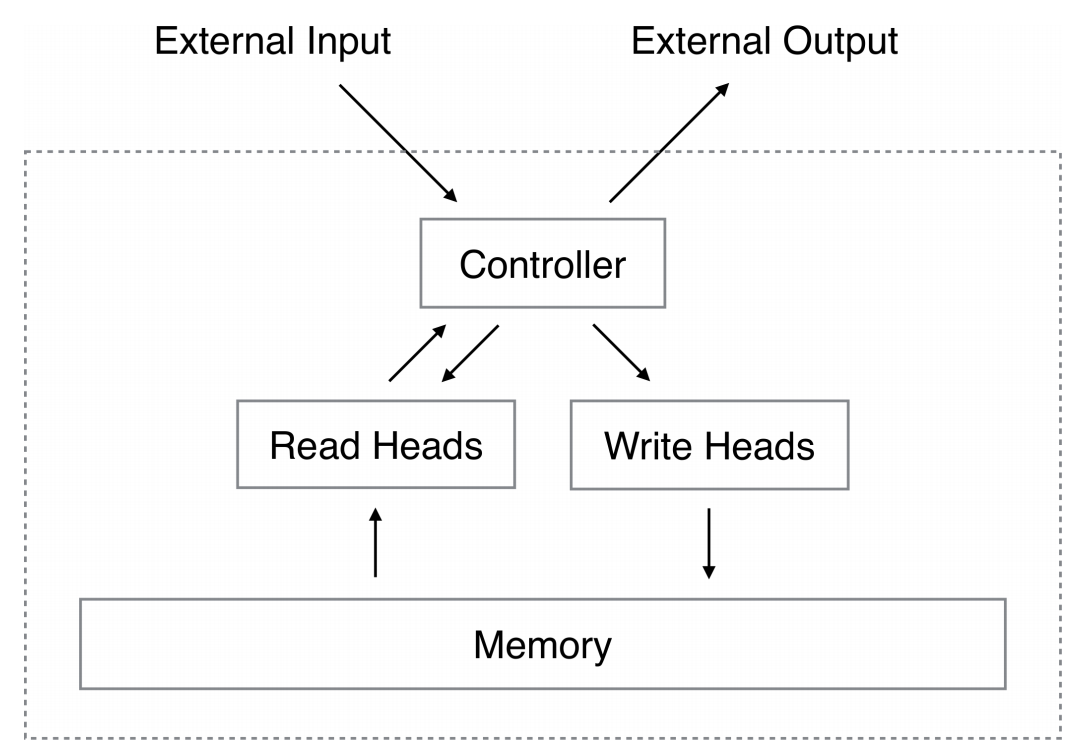
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Question Answering | 4 | 12.12% |
| Automatic Speech Recognition (ASR) | 2 | 6.06% |
| Decoder | 2 | 6.06% |
| Speech Recognition | 2 | 6.06% |
| Retrieval | 2 | 6.06% |
| BIG-bench Machine Learning | 2 | 6.06% |
| Information Retrieval | 2 | 6.06% |
| Machine Translation | 2 | 6.06% |
| Translation | 2 | 6.06% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
 Content-based Attention
Content-based Attention
|
Attention Mechanisms | |
 Location-based Attention
Location-based Attention
|
Attention Mechanisms | |
 LSTM
LSTM
|
Recurrent Neural Networks |
