 Distributed Methods
Distributed Methods
ZeRO
Introduced by Rajbhandari et al. in ZeRO: Memory Optimizations Toward Training Trillion Parameter ModelsZero Redundancy Optimizer (ZeRO) is a sharded data parallel method for distributed training. ZeRODP removes the memory state redundancies across data-parallel processes by partitioning the model states instead of replicating them, and it retains the compute/communication efficiency by retaining the computational granularity and communication volume of DP using a dynamic communication schedule during training.
Source: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models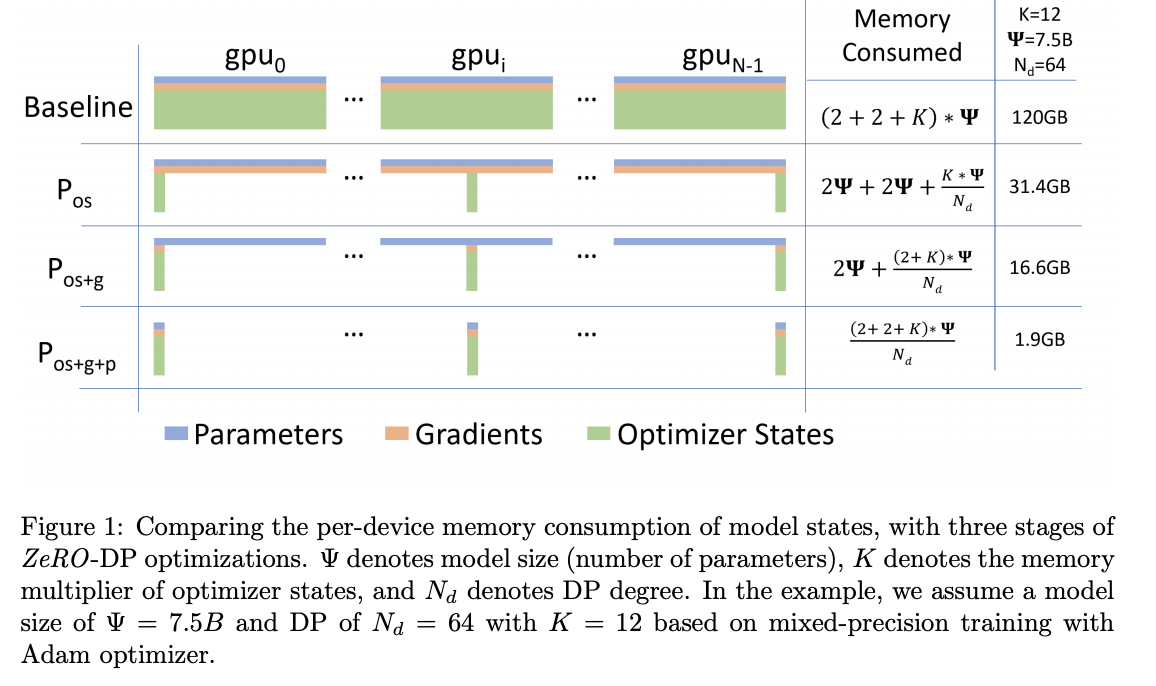
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Quantization | 2 | 28.57% |
| Language Modelling | 2 | 28.57% |
| Large Language Model | 1 | 14.29% |
| Cross-Lingual Document Classification | 1 | 14.29% |
| Image Generation | 1 | 14.29% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |


