Papers with Code Newsletter #33
Welcome to the 33rd issue of the Papers with Code newsletter. This week we cover:
- a large open-source translation model covering 200 languages,
- vision-language for medical image segmentation,
- beyond neural scaling laws,
- top trending papers of June 2022,
- ... and much more.
Open-Source Translation Model Covers 200 Languages!
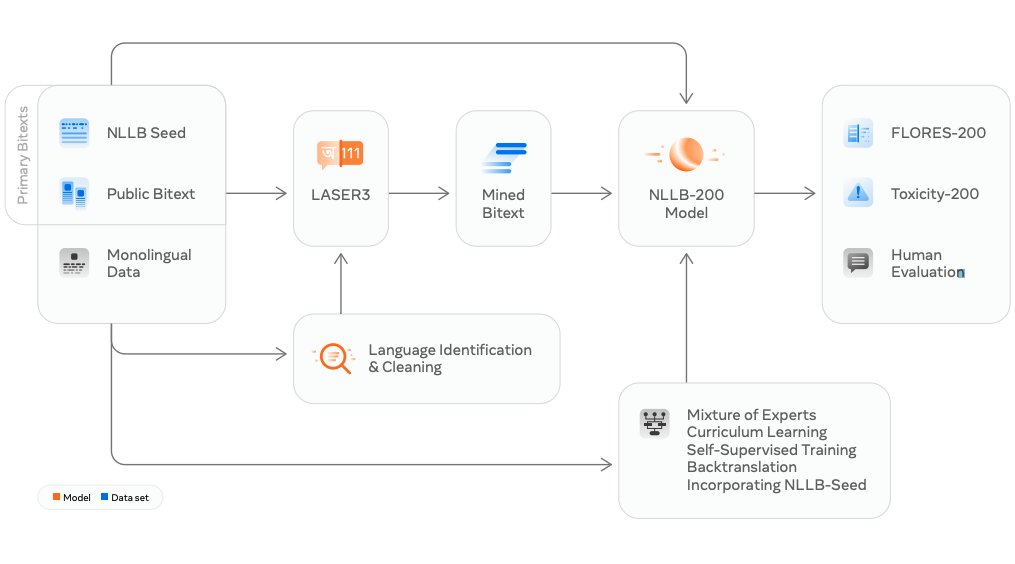
NLLB-200 high-level framework overview.
A lot of the recent progress in machine translation has focused on mid- to high-resource languages. Little progress has been happening in low-resource languages, leaving a huge gap in terms of language coverage. To address this problem, Meta AI researchers introduce a massive translation model (NLLB-200), capable of translating between 200 languages to reduce this gap.
Coined as No Language Left Behind (NLLB), this project introduces an automatic dataset construction approach to improve low-resource language coverage. NLLB-200 is built with a Sparse Mixture-of-Experts model to leverage shared capacity and enable significant improvements in translation for low-resource languages. Regularization techniques, self-supervised learning, and large-scale data augmentation are also used. In addition, the human-verified evaluation benchmark, FLORES-101, is extended 2x to improve on evaluation of translation quality across more languages.
Vision-Language Medical Image Segmentation

LViT architecture overview. Source: Li et al. (2022)
We have seen tremendous progress in computer vision systems applied to complex tasks such as medical image segmentation. One challenge in this space is the lack of high-quality annotated data. Li et al. (2022) recently proposed a new model called LViT which is a new vision-language medical image segmentation model.
Quality deficiency of data is addressed by leveraging textual information to guarantee quality of pseudo labels. This is combined with the LViT model which processes the image and text. Text features are obtained using BERT-based embedding layer. The images are encoded using a hybrid CNN-ViT architecture to better merge textual information, encode global features, and more efficiently extract local features. LViT achieves state-of-the-art in medical image segmentation on MoNuSeg. It also achieves superior performance on QaTa-COV19 dataset.
Beyond Neural Scaling Laws

Figure shows that data pruning improves transfer learning. Source: Sorscher et al. (2022)
Neural scaling laws have attracted a lot of research interest due to the implications it has on efficiently training large neural models. Sorscher et al. (2022) investigates the question of whether it's possible to improve scaling that goes beyond power law. Here is a summary of some of the main findings:
- current practices of collecting large datasets may be highly inefficient; there are good strategies available to effectively prune large amounts of data without sacrificing model performance,
- careful data pruning techniques are able to empirically demonstrate signatures of exponential scaling, giving rise to the usefulness and potential of data pruning as a strategy for large-scale training and pre-training,
- a simple self-supervised pruning metric enables the discarding of 20% of ImageNet without sacrificing performance.
See more results in the paper.
Top Trending Papers for June 2022

Mask DINO Framework. Source: Li et al. (2022)
1️⃣ Mask DINO (Li et al) - extends DINO (DETR with Improved Denoising Anchor Boxes) with a mask prediction branch to support image segmentations tasks (instance, panoptic, and semantic).
2️⃣ Modern Hopfield Networks for Tabular Data(Schäfl et al) - proposes a deep learning architecture based on continuous Hopfield networks for competitive results on small-sized tabular datasets.
3️⃣ Parti (Yu et al) - a new autoregressive model to generate high-fidelity photorealistic images; achieves state-of-the-art zero-shot performance on text-to-image generation on MS-COCO.
4️⃣ EfficientFormer (Li et al) - a model that improves vision transformers for vision tasks; it identifies and addresses design inefficiencies and performs latency-driven slimming which leads to superior performance and speed on mobile devices.
5️⃣ CFA for Target-Oriented Anomaly Localization (Lee et al) - proposes the use of coupled-hypersphere-based feature adaptation for anomaly localization using features adapted to the target dataset.

PIDNet results showing best trade-off between inference speed and accuracy for real-time models. Source: Xu et al. (2022)
6️⃣ PIDNet (Xu et al) - a three-branch network architecture for real-time semantic segmentation inspired from PID controller; achieves best trade-off between inference speed and accuracy with high performance on Cityscapes, CamVid, and COCO-Stuff dataset.
7️⃣ Pythae (Chadebec et al) - a python library that provides implementations of the most common autoencoder models.
8️⃣ PointNeXt (Qian et al) - a systematic study of model training and scaling strategies to improve PointNet++; PointNeXt (next version of PointNets) can be scaled up to outperform state-of-the-art methods on 3D classification and segmentation tasks.
9️⃣ HaGRID (Kapitanov et al) - a large image dataset for hand gesture recognition systems; contains ~553K FullHD RGB images divided into 18 classes of gestures.
🔟 Vision GNN (Han et al) - a new vision GNN architecture to extract graph-level features for visual tasks; images are represented as a graph structure with the attempt to capture irregular and complex objects.
Benchmark, Datasets & Tools

ArtBench-10 preview. Source: Liao et al. (2022)
ArtBench-10 - a high-quality dataset for benchmarking artwork generation; it comprises 60,000 images of artwork from 10 distinctive artistic styles, with 5K training images and 1K testing images per style.
Pile of Law - a 256GB dataset of legal and administrative data for assessing norms on data sanitization across legal and administrative settings.
AnoShift - a distribution shift benchmark for unsupervised anomaly detection.
