3D Shape Reconstruction from 2D Images with Disentangled Attribute Flow
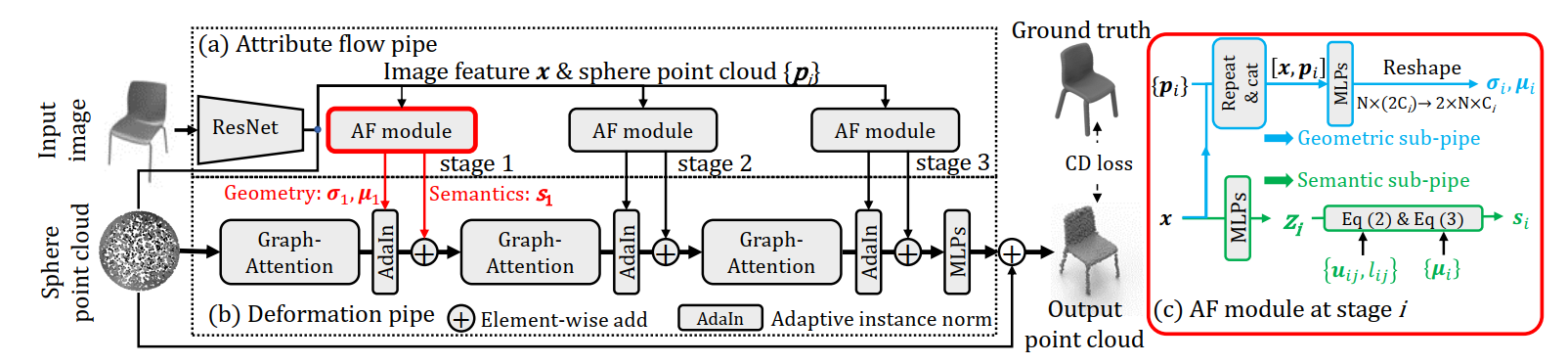
Reconstructing 3D shape from a single 2D image is a challenging task, which needs to estimate the detailed 3D structures based on the semantic attributes from 2D image. So far, most of the previous methods still struggle to extract semantic attributes for 3D reconstruction task. Since the semantic attributes of a single image are usually implicit and entangled with each other, it is still challenging to reconstruct 3D shape with detailed semantic structures represented by the input image. To address this problem, we propose 3DAttriFlow to disentangle and extract semantic attributes through different semantic levels in the input images. These disentangled semantic attributes will be integrated into the 3D shape reconstruction process, which can provide definite guidance to the reconstruction of specific attribute on 3D shape. As a result, the 3D decoder can explicitly capture high-level semantic features at the bottom of the network, and utilize low-level features at the top of the network, which allows to reconstruct more accurate 3D shapes. Note that the explicit disentangling is learned without extra labels, where the only supervision used in our training is the input image and its corresponding 3D shape. Our comprehensive experiments on ShapeNet dataset demonstrate that 3DAttriFlow outperforms the state-of-the-art shape reconstruction methods, and we also validate its generalization ability on shape completion task.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract



 ShapeNet
ShapeNet
 MVP
MVP
