SSMBA: Self-Supervised Manifold Based Data Augmentation for Improving Out-of-Domain Robustness
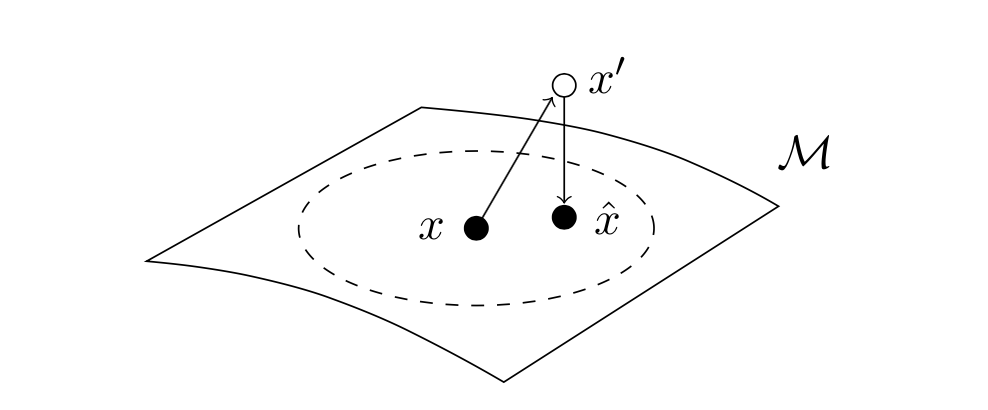
Models that perform well on a training domain often fail to generalize to out-of-domain (OOD) examples. Data augmentation is a common method used to prevent overfitting and improve OOD generalization. However, in natural language, it is difficult to generate new examples that stay on the underlying data manifold. We introduce SSMBA, a data augmentation method for generating synthetic training examples by using a pair of corruption and reconstruction functions to move randomly on a data manifold. We investigate the use of SSMBA in the natural language domain, leveraging the manifold assumption to reconstruct corrupted text with masked language models. In experiments on robustness benchmarks across 3 tasks and 9 datasets, SSMBA consistently outperforms existing data augmentation methods and baseline models on both in-domain and OOD data, achieving gains of 0.8% accuracy on OOD Amazon reviews, 1.8% accuracy on OOD MNLI, and 1.4 BLEU on in-domain IWSLT14 German-English.
PDF Abstract EMNLP 2020 PDF EMNLP 2020 Abstract

 SST
SST
 MultiNLI
MultiNLI
 IMDb Movie Reviews
IMDb Movie Reviews
 ANLI
ANLI
