KinyaBERT: a Morphology-aware Kinyarwanda Language Model
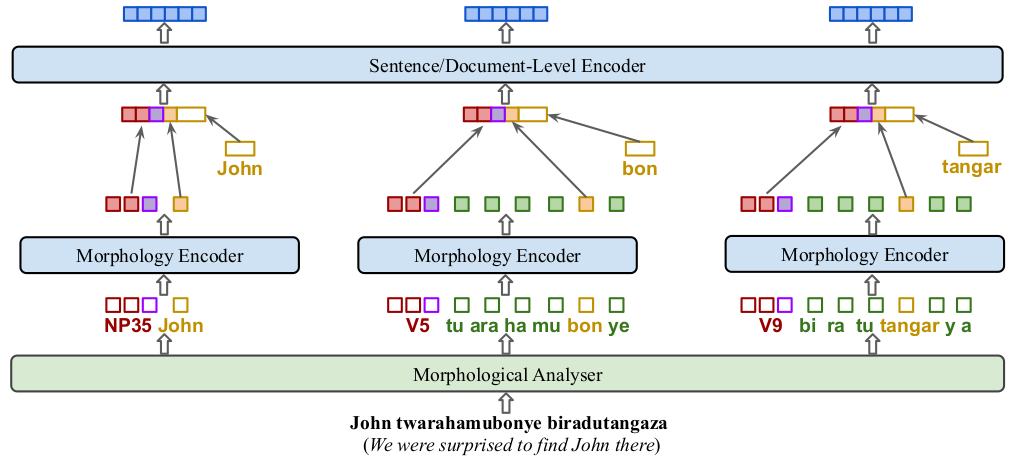
Pre-trained language models such as BERT have been successful at tackling many natural language processing tasks. However, the unsupervised sub-word tokenization methods commonly used in these models (e.g., byte-pair encoding - BPE) are sub-optimal at handling morphologically rich languages. Even given a morphological analyzer, naive sequencing of morphemes into a standard BERT architecture is inefficient at capturing morphological compositionality and expressing word-relative syntactic regularities. We address these challenges by proposing a simple yet effective two-tier BERT architecture that leverages a morphological analyzer and explicitly represents morphological compositionality. Despite the success of BERT, most of its evaluations have been conducted on high-resource languages, obscuring its applicability on low-resource languages. We evaluate our proposed method on the low-resource morphologically rich Kinyarwanda language, naming the proposed model architecture KinyaBERT. A robust set of experimental results reveal that KinyaBERT outperforms solid baselines by 2% in F1 score on a named entity recognition task and by 4.3% in average score of a machine-translated GLUE benchmark. KinyaBERT fine-tuning has better convergence and achieves more robust results on multiple tasks even in the presence of translation noise.
PDF Abstract ACL 2022 PDF ACL 2022 Abstract



 GLUE
GLUE
 QNLI
QNLI
