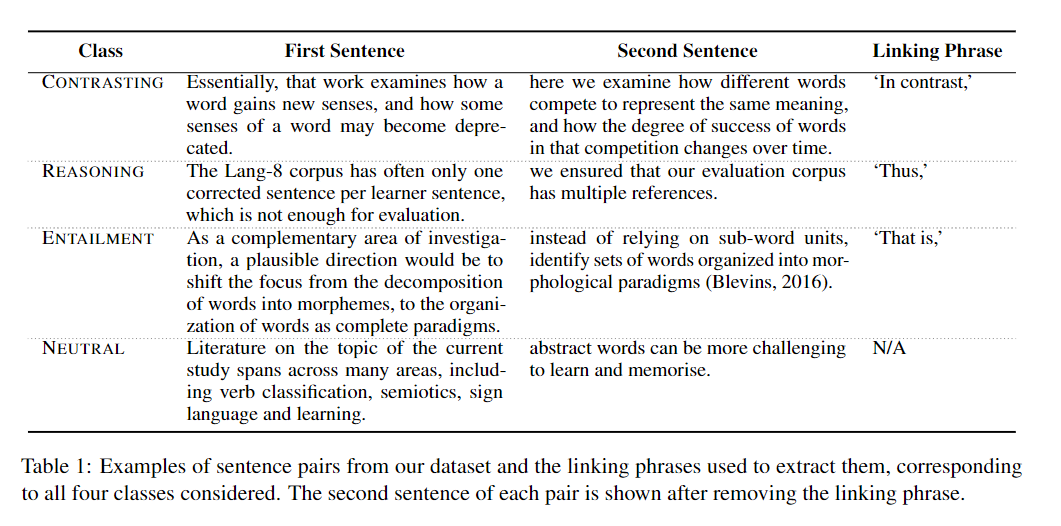
SciNLI: A Corpus for Natural Language Inference on Scientific Text
Existing Natural Language Inference (NLI) datasets, while being instrumental in the advancement of Natural Language Understanding (NLU) research, are not related to scientific text. In this paper, we introduce SciNLI, a large dataset for NLI that captures the formality in scientific text and contains 107,412 sentence pairs extracted from scholarly papers on NLP and computational linguistics. Given that the text used in scientific literature differs vastly from the text used in everyday language both in terms of vocabulary and sentence structure, our dataset is well suited to serve as a benchmark for the evaluation of scientific NLU models. Our experiments show that SciNLI is harder to classify than the existing NLI datasets. Our best performing model with XLNet achieves a Macro F1 score of only 78.18% and an accuracy of 78.23% showing that there is substantial room for improvement.
PDF Abstract ACL 2022 PDF ACL 2022 Abstract


 GLUE
GLUE
 MultiNLI
MultiNLI
 SNLI
SNLI
 SICK
SICK
 ANLI
ANLI
 SWAG
SWAG
