A Large-Scale Chinese Short-Text Conversation Dataset
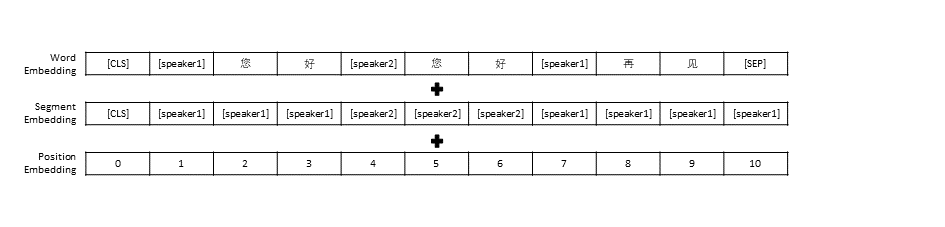
The advancements of neural dialogue generation models show promising results on modeling short-text conversations. However, training such models usually needs a large-scale high-quality dialogue corpus, which is hard to access. In this paper, we present a large-scale cleaned Chinese conversation dataset, LCCC, which contains a base version (6.8million dialogues) and a large version (12.0 million dialogues). The quality of our dataset is ensured by a rigorous data cleaning pipeline, which is built based on a set of rules and a classifier that is trained on manually annotated 110K dialogue pairs. We also release pre-training dialogue models which are trained on LCCC-base and LCCC-large respectively. The cleaned dataset and the pre-training models will facilitate the research of short-text conversation modeling. All the models and datasets are available at https://github.com/thu-coai/CDial-GPT.
PDF AbstractCode



Datasets
Introduced in the Paper:
LCCCUsed in the Paper:
 OpenSubtitles
OpenSubtitles
 Wizard of Wikipedia
Douban
Douban Conversation Corpus
Wizard of Wikipedia
Douban
Douban Conversation Corpus
