A Multi-Stage Multi-Codebook VQ-VAE Approach to High-Performance Neural TTS
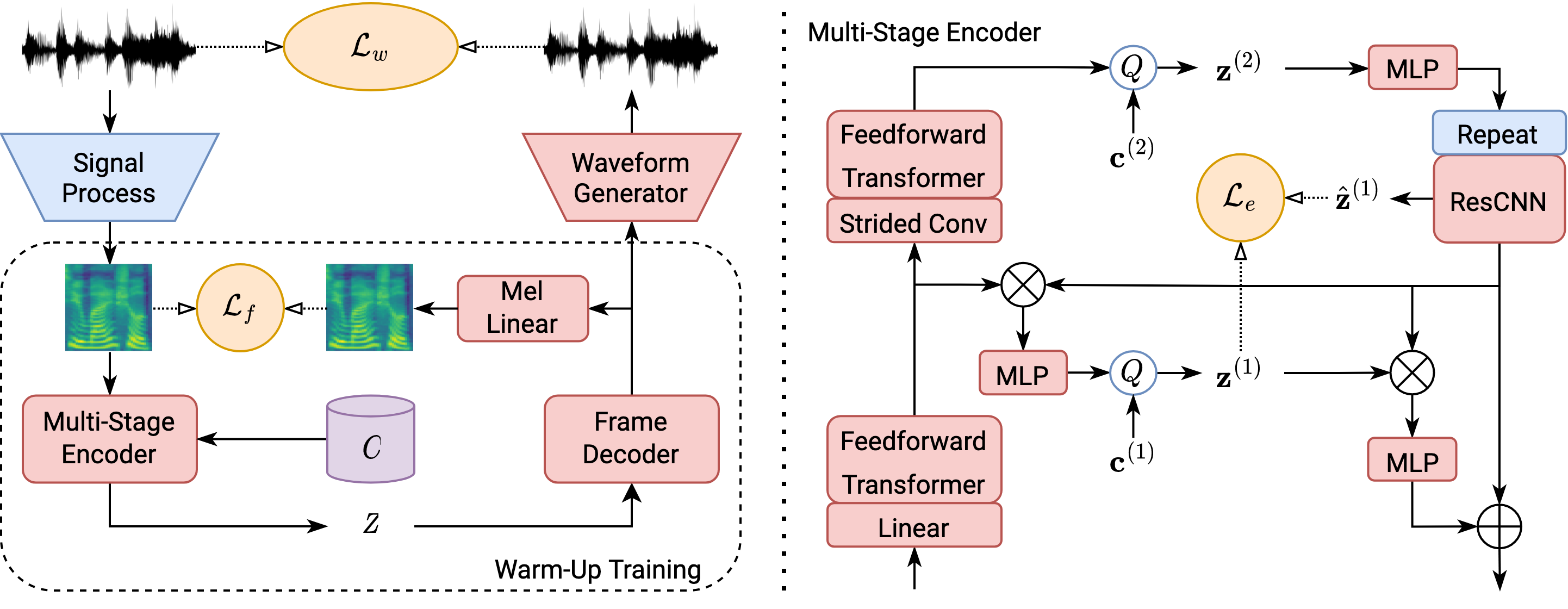
We propose a Multi-Stage, Multi-Codebook (MSMC) approach to high-performance neural TTS synthesis. A vector-quantized, variational autoencoder (VQ-VAE) based feature analyzer is used to encode Mel spectrograms of speech training data by down-sampling progressively in multiple stages into MSMC Representations (MSMCRs) with different time resolutions, and quantizing them with multiple VQ codebooks, respectively. Multi-stage predictors are trained to map the input text sequence to MSMCRs progressively by minimizing a combined loss of the reconstruction Mean Square Error (MSE) and "triplet loss". In synthesis, the neural vocoder converts the predicted MSMCRs into final speech waveforms. The proposed approach is trained and tested with an English TTS database of 16 hours by a female speaker. The proposed TTS achieves an MOS score of 4.41, which outperforms the baseline with an MOS of 3.62. Compact versions of the proposed TTS with much less parameters can still preserve high MOS scores. Ablation studies show that both multiple stages and multiple codebooks are effective for achieving high TTS performance.
PDF Abstract
