A Self-supervised Approach for Adversarial Robustness
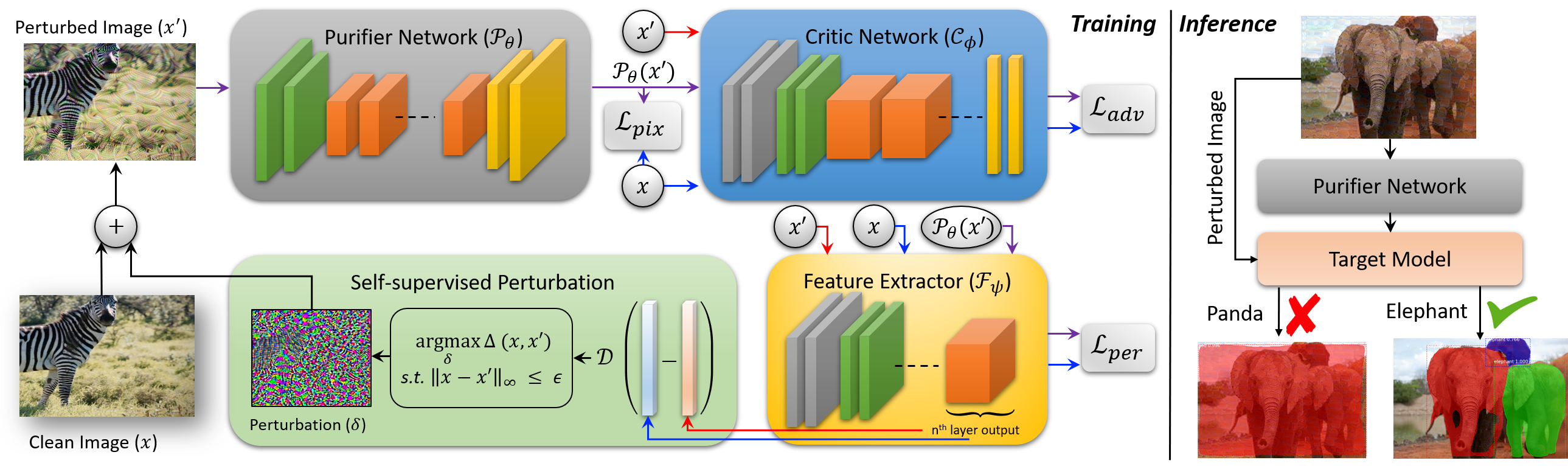
Adversarial examples can cause catastrophic mistakes in Deep Neural Network (DNNs) based vision systems e.g., for classification, segmentation and object detection. The vulnerability of DNNs against such attacks can prove a major roadblock towards their real-world deployment. Transferability of adversarial examples demand generalizable defenses that can provide cross-task protection. Adversarial training that enhances robustness by modifying target model's parameters lacks such generalizability. On the other hand, different input processing based defenses fall short in the face of continuously evolving attacks. In this paper, we take the first step to combine the benefits of both approaches and propose a self-supervised adversarial training mechanism in the input space. By design, our defense is a generalizable approach and provides significant robustness against the \textbf{unseen} adversarial attacks (\eg by reducing the success rate of translation-invariant \textbf{ensemble} attack from 82.6\% to 31.9\% in comparison to previous state-of-the-art). It can be deployed as a plug-and-play solution to protect a variety of vision systems, as we demonstrate for the case of classification, segmentation and detection. Code is available at: {\small\url{https://github.com/Muzammal-Naseer/NRP}}.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract



 MS COCO
MS COCO
