A Survey of Privacy-Preserving Model Explanations: Privacy Risks, Attacks, and Countermeasures
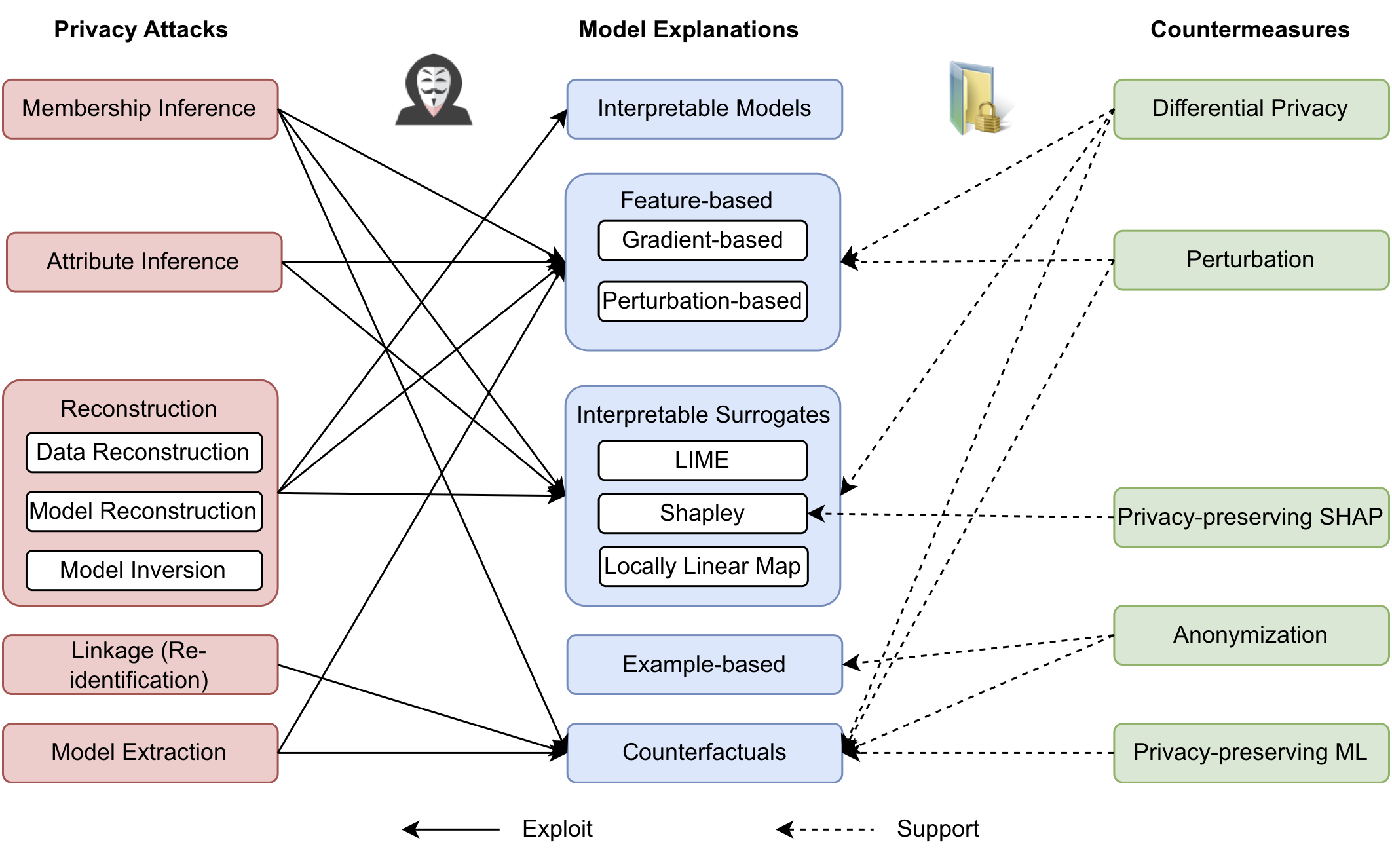
As the adoption of explainable AI (XAI) continues to expand, the urgency to address its privacy implications intensifies. Despite a growing corpus of research in AI privacy and explainability, there is little attention on privacy-preserving model explanations. This article presents the first thorough survey about privacy attacks on model explanations and their countermeasures. Our contribution to this field comprises a thorough analysis of research papers with a connected taxonomy that facilitates the categorisation of privacy attacks and countermeasures based on the targeted explanations. This work also includes an initial investigation into the causes of privacy leaks. Finally, we discuss unresolved issues and prospective research directions uncovered in our analysis. This survey aims to be a valuable resource for the research community and offers clear insights for those new to this domain. To support ongoing research, we have established an online resource repository, which will be continuously updated with new and relevant findings. Interested readers are encouraged to access our repository at https://github.com/tamlhp/awesome-privex.
PDF Abstract
 SVHN
SVHN
 Food-101
Food-101
