A Survey on Multimodal Large Language Models
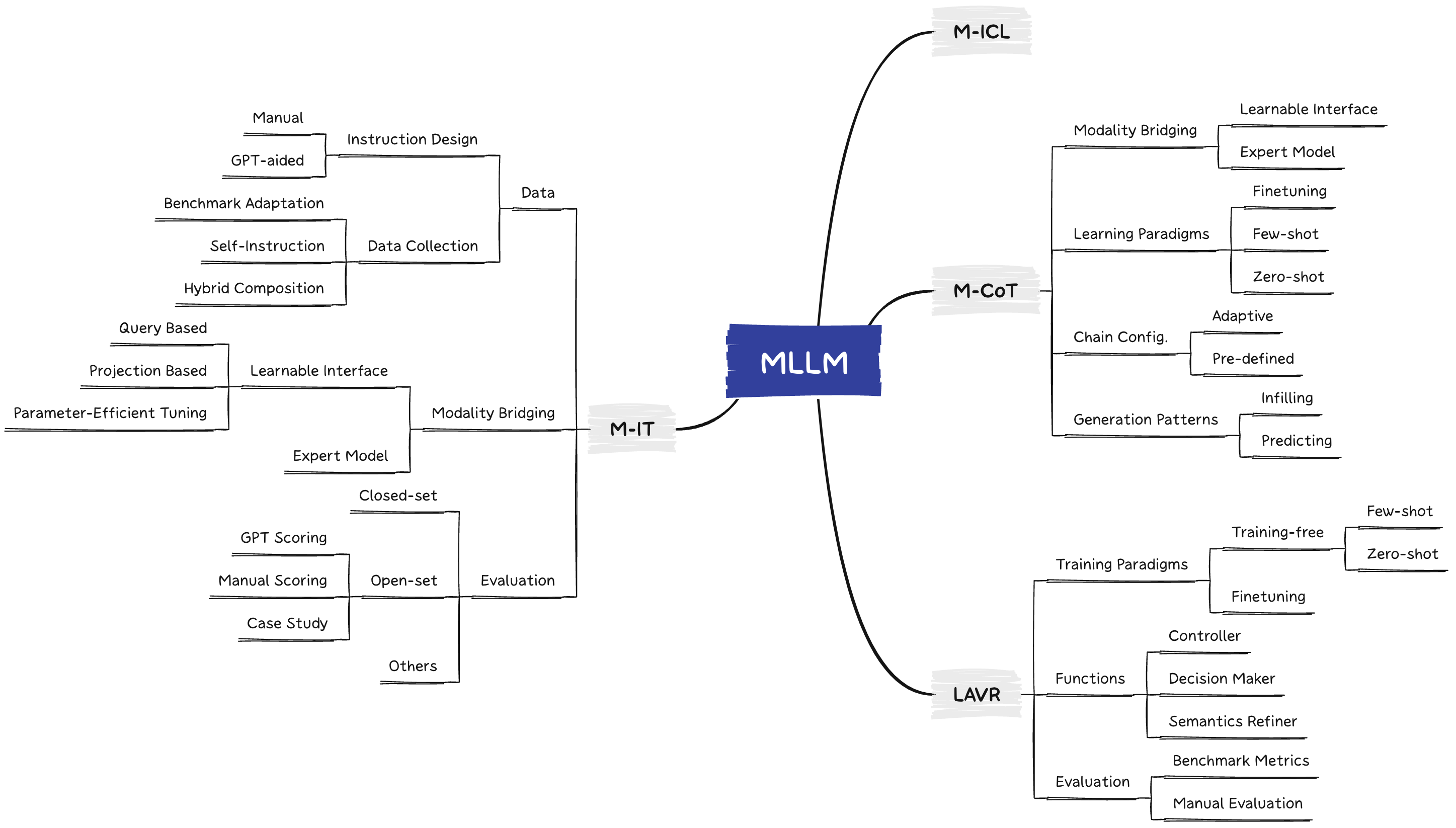
Recently, Multimodal Large Language Model (MLLM) represented by GPT-4V has been a new rising research hotspot, which uses powerful Large Language Models (LLMs) as a brain to perform multimodal tasks. The surprising emergent capabilities of MLLM, such as writing stories based on images and OCR-free math reasoning, are rare in traditional multimodal methods, suggesting a potential path to artificial general intelligence. To this end, both academia and industry have endeavored to develop MLLMs that can compete with or even better than GPT-4V, pushing the limit of research at a surprising speed. In this paper, we aim to trace and summarize the recent progress of MLLMs. First of all, we present the basic formulation of MLLM and delineate its related concepts, including architecture, training strategy and data, as well as evaluation. Then, we introduce research topics about how MLLMs can be extended to support more granularity, modalities, languages, and scenarios. We continue with multimodal hallucination and extended techniques, including Multimodal ICL (M-ICL), Multimodal CoT (M-CoT), and LLM-Aided Visual Reasoning (LAVR). To conclude the paper, we discuss existing challenges and point out promising research directions. In light of the fact that the era of MLLM has only just begun, we will keep updating this survey and hope it can inspire more research. An associated GitHub link collecting the latest papers is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models.
PDF Abstract Colab
Colab
 Spaces
Spaces



 MS COCO
MS COCO
 Flickr30k
Flickr30k
 ScienceQA
ScienceQA
 LAION-5B
LAION-5B
 CC12M
CC12M
