A Survey on Offline Reinforcement Learning: Taxonomy, Review, and Open Problems
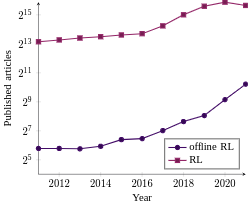
With the widespread adoption of deep learning, reinforcement learning (RL) has experienced a dramatic increase in popularity, scaling to previously intractable problems, such as playing complex games from pixel observations, sustaining conversations with humans, and controlling robotic agents. However, there is still a wide range of domains inaccessible to RL due to the high cost and danger of interacting with the environment. Offline RL is a paradigm that learns exclusively from static datasets of previously collected interactions, making it feasible to extract policies from large and diverse training datasets. Effective offline RL algorithms have a much wider range of applications than online RL, being particularly appealing for real-world applications, such as education, healthcare, and robotics. In this work, we contribute with a unifying taxonomy to classify offline RL methods. Furthermore, we provide a comprehensive review of the latest algorithmic breakthroughs in the field using a unified notation as well as a review of existing benchmarks' properties and shortcomings. Additionally, we provide a figure that summarizes the performance of each method and class of methods on different dataset properties, equipping researchers with the tools to decide which type of algorithm is best suited for the problem at hand and identify which classes of algorithms look the most promising. Finally, we provide our perspective on open problems and propose future research directions for this rapidly growing field.
PDF Abstract
 D4RL
D4RL
