Accelerating Diffusion-Based Text-to-Audio Generation with Consistency Distillation
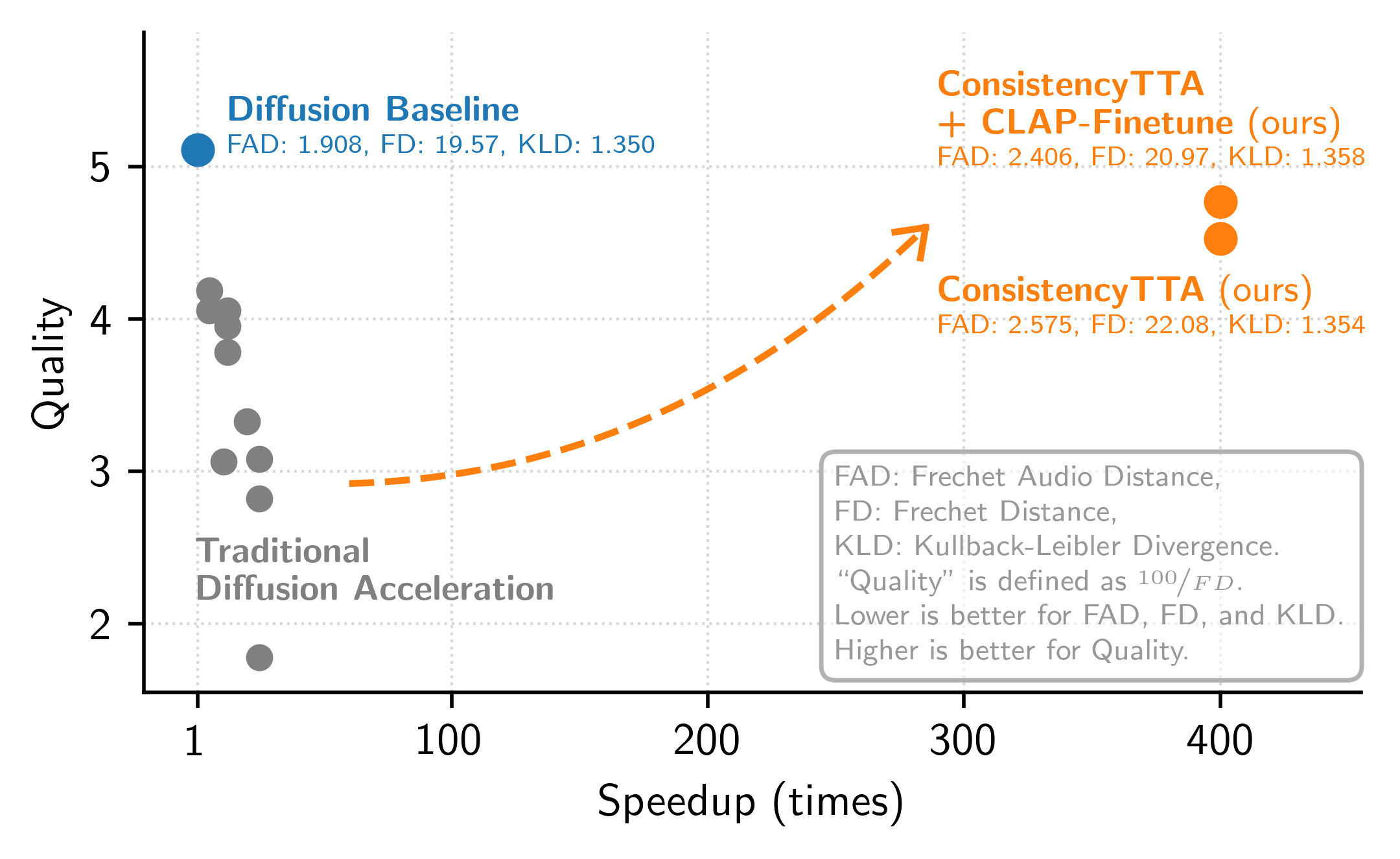
Diffusion models power a vast majority of text-to-audio (TTA) generation methods. Unfortunately, these models suffer from slow inference speed due to iterative queries to the underlying denoising network, thus unsuitable for scenarios with inference time or computational constraints. This work modifies the recently proposed consistency distillation framework to train TTA models that require only a single neural network query. In addition to incorporating classifier-free guidance into the distillation process, we leverage the availability of generated audio during distillation training to fine-tune the consistency TTA model with novel loss functions in the audio space, such as the CLAP score. Our objective and subjective evaluation results on the AudioCaps dataset show that consistency models retain diffusion models' high generation quality and diversity while reducing the number of queries by a factor of 400.
PDF Abstract



 AudioSet
AudioSet
 AudioCaps
AudioCaps

