SPEED: Separable Pyramidal Pooling EncodEr-Decoder for Real-Time Monocular Depth Estimation on Low-Resource Settings
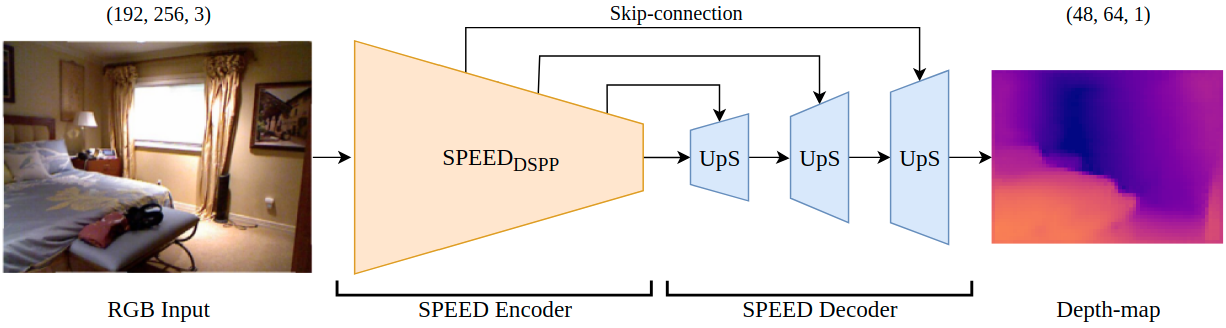
The monocular depth estimation (MDE) is the task of estimating depth from a single frame. This information is an essential knowledge in many computer vision tasks such as scene understanding and visual odometry, which are key components in autonomous and robotic systems. Approaches based on the state of the art vision transformer architectures are extremely deep and complex not suitable for real-time inference operations on edge and autonomous systems equipped with low resources (i.e. robot indoor navigation and surveillance). This paper presents SPEED, a Separable Pyramidal pooling EncodEr-Decoder architecture designed to achieve real-time frequency performances on multiple hardware platforms. The proposed model is a fast-throughput deep architecture for MDE able to obtain depth estimations with high accuracy from low resolution images using minimum hardware resources (i.e. edge devices). Our encoder-decoder model exploits two depthwise separable pyramidal pooling layers, which allow to increase the inference frequency while reducing the overall computational complexity. The proposed method performs better than other fast-throughput architectures in terms of both accuracy and frame rates, achieving real-time performances over cloud CPU, TPU and the NVIDIA Jetson TX1 on two indoor benchmarks: the NYU Depth v2 and the DIML Kinect v2 datasets.
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Language Modelling | 25 | 4.33% |
| Quantization | 20 | 3.47% |
| Object Detection | 15 | 2.60% |
| Semantic Segmentation | 13 | 2.25% |
| Large Language Model | 13 | 2.25% |
| Image Generation | 13 | 2.25% |
| Decision Making | 12 | 2.08% |
| Autonomous Driving | 11 | 1.91% |
| Federated Learning | 11 | 1.91% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
