ADAPT: Action-aware Driving Caption Transformer
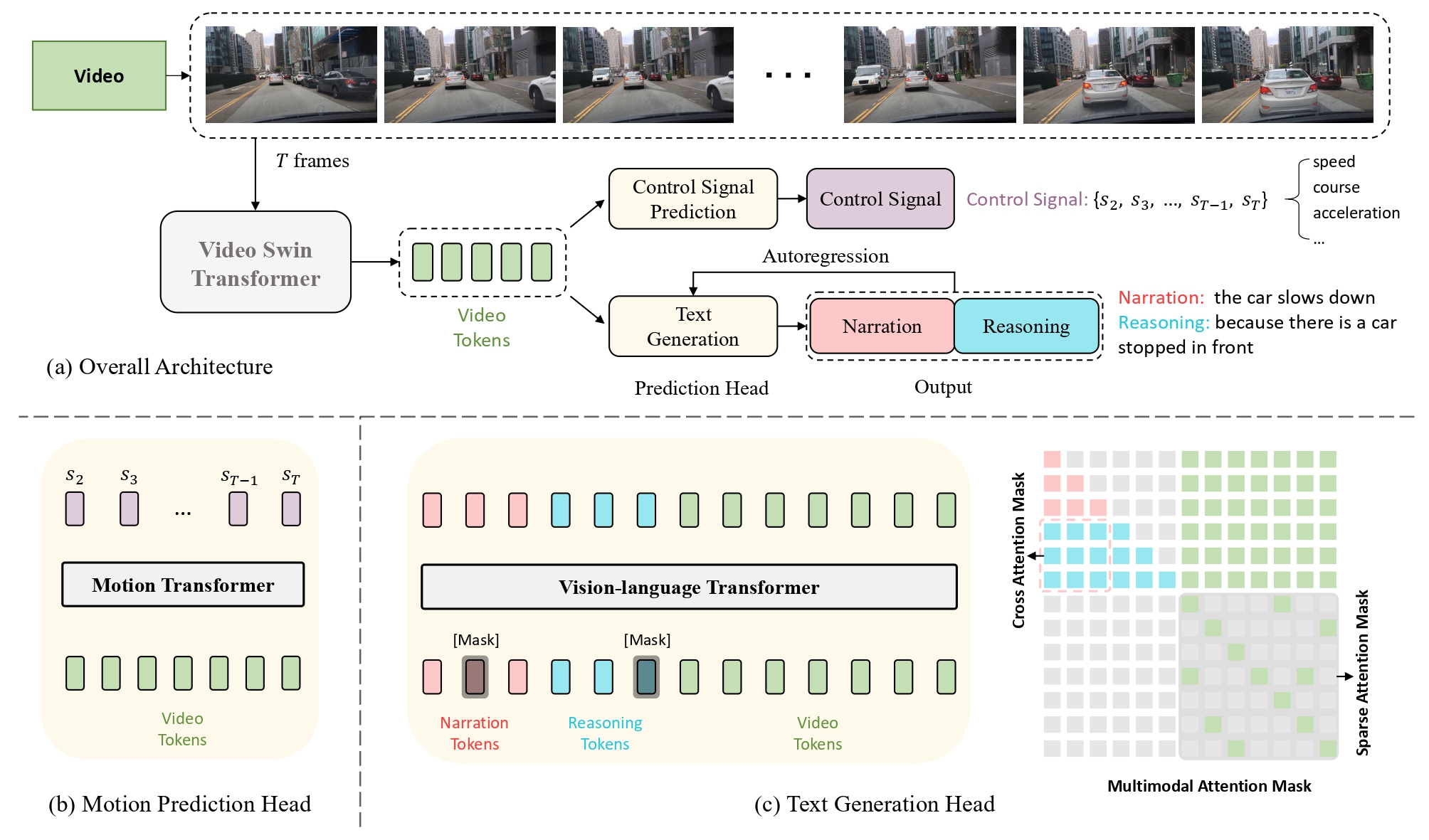
End-to-end autonomous driving has great potential in the transportation industry. However, the lack of transparency and interpretability of the automatic decision-making process hinders its industrial adoption in practice. There have been some early attempts to use attention maps or cost volume for better model explainability which is difficult for ordinary passengers to understand. To bridge the gap, we propose an end-to-end transformer-based architecture, ADAPT (Action-aware Driving cAPtion Transformer), which provides user-friendly natural language narrations and reasoning for each decision making step of autonomous vehicular control and action. ADAPT jointly trains both the driving caption task and the vehicular control prediction task, through a shared video representation. Experiments on BDD-X (Berkeley DeepDrive eXplanation) dataset demonstrate state-of-the-art performance of the ADAPT framework on both automatic metrics and human evaluation. To illustrate the feasibility of the proposed framework in real-world applications, we build a novel deployable system that takes raw car videos as input and outputs the action narrations and reasoning in real time. The code, models and data are available at https://github.com/jxbbb/ADAPT.
PDF Abstract


 BDD-X
BDD-X
