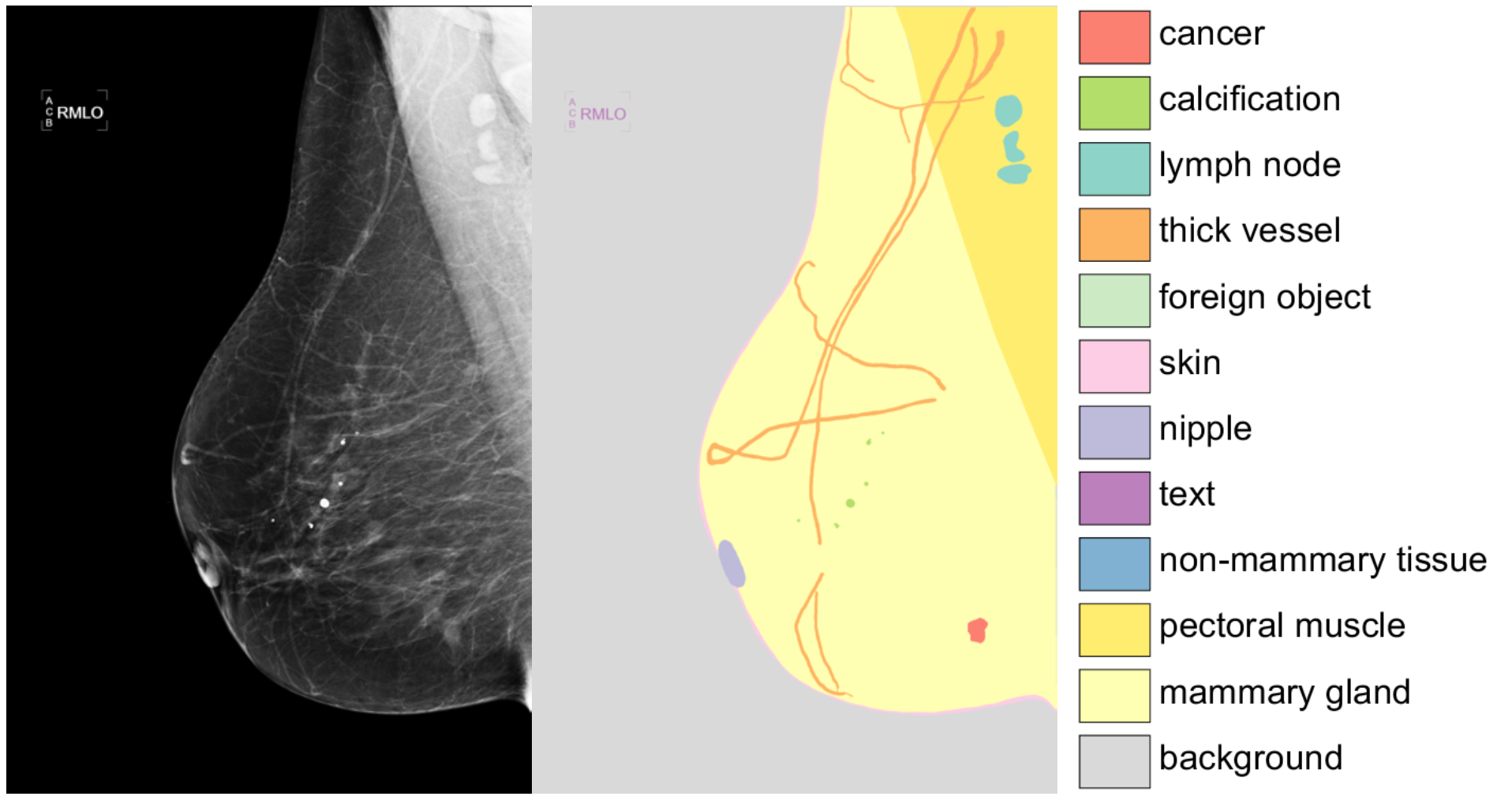
Adding Seemingly Uninformative Labels Helps in Low Data Regimes
Evidence suggests that networks trained on large datasets generalize well not solely because of the numerous training examples, but also class diversity which encourages learning of enriched features. This raises the question of whether this remains true when data is scarce - is there an advantage to learning with additional labels in low-data regimes? In this work, we consider a task that requires difficult-to-obtain expert annotations: tumor segmentation in mammography images. We show that, in low-data settings, performance can be improved by complementing the expert annotations with seemingly uninformative labels from non-expert annotators, turning the task into a multi-class problem. We reveal that these gains increase when less expert data is available, and uncover several interesting properties through further studies. We demonstrate our findings on CSAW-S, a new dataset that we introduce here, and confirm them on two public datasets.
PDF Abstract ICML 2020 PDF
Tasks

Datasets
Introduced in the Paper:
 CSAW-S
CSAW-S
