Adversarial Semi-Supervised Audio Source Separation applied to Singing Voice Extraction
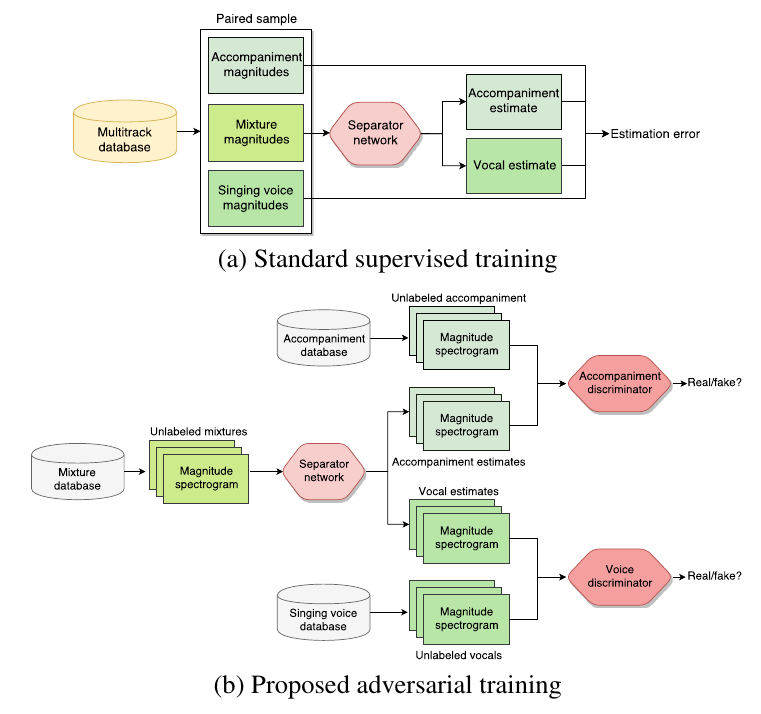
The state of the art in music source separation employs neural networks trained in a supervised fashion on multi-track databases to estimate the sources from a given mixture. With only few datasets available, often extensive data augmentation is used to combat overfitting. Mixing random tracks, however, can even reduce separation performance as instruments in real music are strongly correlated. The key concept in our approach is that source estimates of an optimal separator should be indistinguishable from real source signals. Based on this idea, we drive the separator towards outputs deemed as realistic by discriminator networks that are trained to tell apart real from separator samples. This way, we can also use unpaired source and mixture recordings without the drawbacks of creating unrealistic music mixtures. Our framework is widely applicable as it does not assume a specific network architecture or number of sources. To our knowledge, this is the first adoption of adversarial training for music source separation. In a prototype experiment for singing voice separation, separation performance increases with our approach compared to purely supervised training.
PDF Abstract



 MedleyDB
MedleyDB
