Anatomy-aware 3D Human Pose Estimation with Bone-based Pose Decomposition
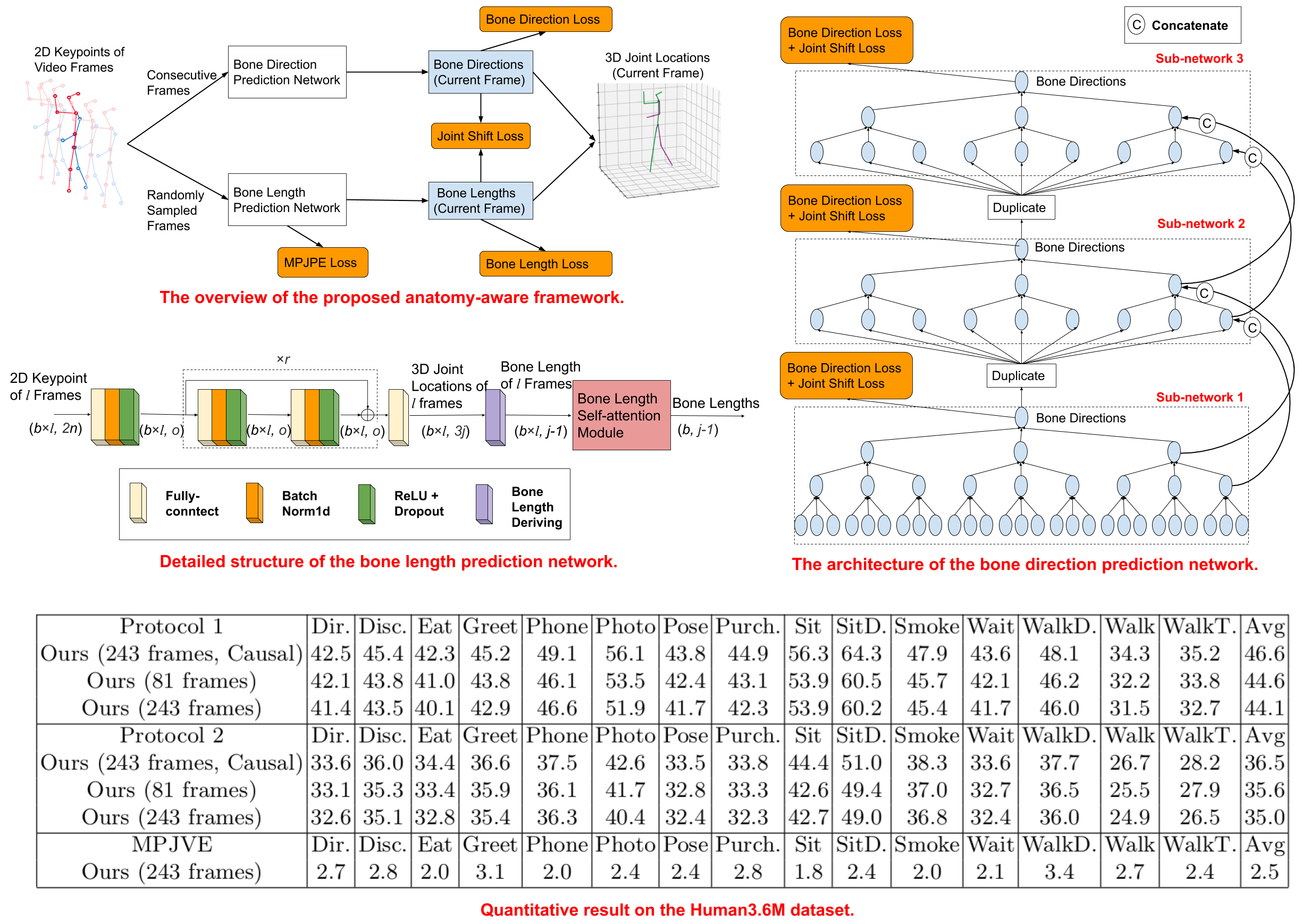
In this work, we propose a new solution to 3D human pose estimation in videos. Instead of directly regressing the 3D joint locations, we draw inspiration from the human skeleton anatomy and decompose the task into bone direction prediction and bone length prediction, from which the 3D joint locations can be completely derived. Our motivation is the fact that the bone lengths of a human skeleton remain consistent across time. This promotes us to develop effective techniques to utilize global information across all the frames in a video for high-accuracy bone length prediction. Moreover, for the bone direction prediction network, we propose a fully-convolutional propagating architecture with long skip connections. Essentially, it predicts the directions of different bones hierarchically without using any time-consuming memory units e.g. LSTM). A novel joint shift loss is further introduced to bridge the training of the bone length and bone direction prediction networks. Finally, we employ an implicit attention mechanism to feed the 2D keypoint visibility scores into the model as extra guidance, which significantly mitigates the depth ambiguity in many challenging poses. Our full model outperforms the previous best results on Human3.6M and MPI-INF-3DHP datasets, where comprehensive evaluation validates the effectiveness of our model.
PDF Abstract



 Human3.6M
Human3.6M
 MPI-INF-3DHP
MPI-INF-3DHP

