Animatable Neural Radiance Fields from Monocular RGB Videos
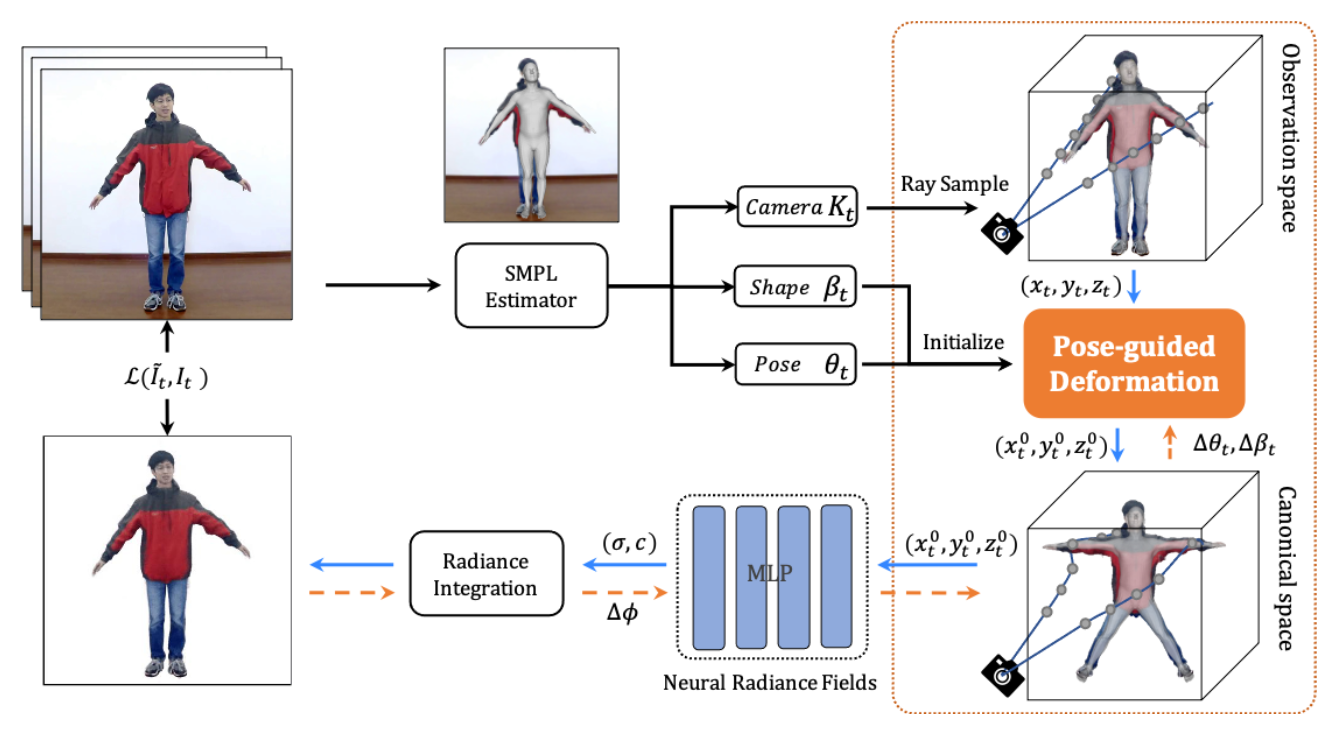
We present animatable neural radiance fields (animatable NeRF) for detailed human avatar creation from monocular videos. Our approach extends neural radiance fields (NeRF) to the dynamic scenes with human movements via introducing explicit pose-guided deformation while learning the scene representation network. In particular, we estimate the human pose for each frame and learn a constant canonical space for the detailed human template, which enables natural shape deformation from the observation space to the canonical space under the explicit control of the pose parameters. To compensate for inaccurate pose estimation, we introduce the pose refinement strategy that updates the initial pose during the learning process, which not only helps to learn more accurate human reconstruction but also accelerates the convergence. In experiments we show that the proposed approach achieves 1) implicit human geometry and appearance reconstruction with high-quality details, 2) photo-realistic rendering of the human from novel views, and 3) animation of the human with novel poses.
PDF Abstract



