ASiT: Local-Global Audio Spectrogram vIsion Transformer for Event Classification
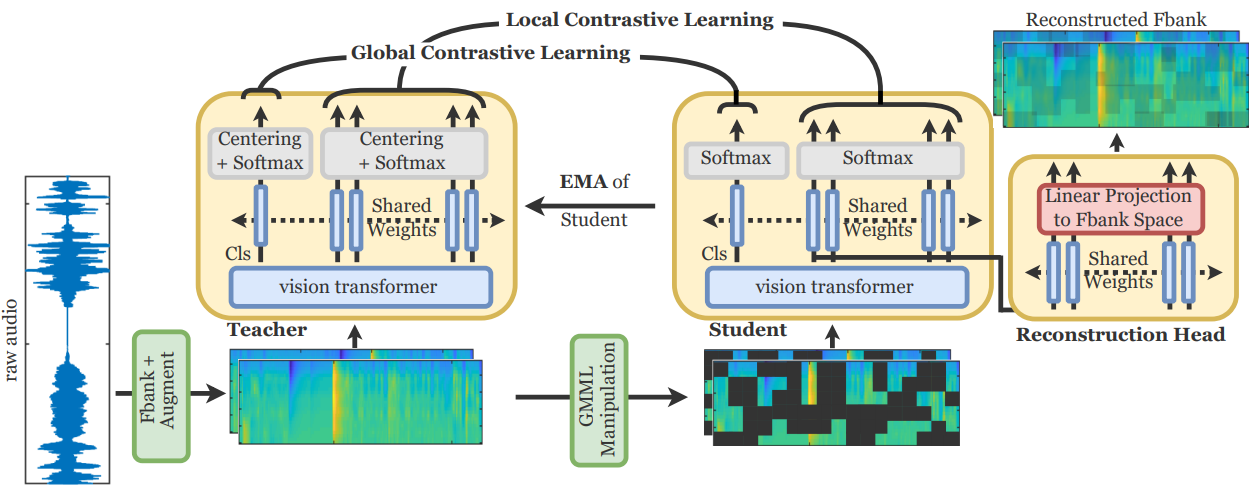
Transformers, which were originally developed for natural language processing, have recently generated significant interest in the computer vision and audio communities due to their flexibility in learning long-range relationships. Constrained by the data hungry nature of transformers and the limited amount of labelled data, most transformer-based models for audio tasks are finetuned from ImageNet pretrained models, despite the huge gap between the domain of natural images and audio. This has motivated the research in self-supervised pretraining of audio transformers, which reduces the dependency on large amounts of labeled data and focuses on extracting concise representations of audio spectrograms. In this paper, we propose \textbf{L}ocal-\textbf{G}lobal \textbf{A}udio \textbf{S}pectrogram v\textbf{I}sion \textbf{T}ransformer, namely ASiT, a novel self-supervised learning framework that captures local and global contextual information by employing group masked model learning and self-distillation. We evaluate our pretrained models on both audio and speech classification tasks, including audio event classification, keyword spotting, and speaker identification. We further conduct comprehensive ablation studies, including evaluations of different pretraining strategies. The proposed ASiT framework significantly boosts the performance on all tasks and sets a new state-of-the-art performance in five audio and speech classification tasks, outperforming recent methods, including the approaches that use additional datasets for pretraining.
PDF Abstract



 LibriSpeech
LibriSpeech
 Speech Commands
Speech Commands
 ESC-50
ESC-50
