LibriSpeech
Introduced by Vassil Panayotov et al. in Librispeech: An ASR corpus based on public domain audio books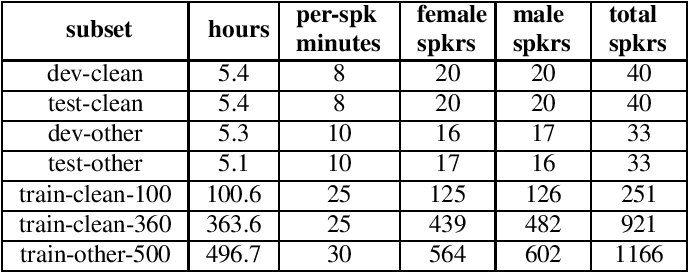
The LibriSpeech corpus is a collection of approximately 1,000 hours of audiobooks that are a part of the LibriVox project. Most of the audiobooks come from the Project Gutenberg. The training data is split into 3 partitions of 100hr, 360hr, and 500hr sets while the dev and test data are split into the ’clean’ and ’other’ categories, respectively, depending upon how well or challenging Automatic Speech Recognition systems would perform against. Each of the dev and test sets is around 5hr in audio length. This corpus also provides the n-gram language models and the corresponding texts excerpted from the Project Gutenberg books, which contain 803M tokens and 977K unique words.
Source: State-of-the-art Speech Recognition using Multi-stream Self-attention with Dilated 1D ConvolutionsBenchmarks
| Trend | Task | Dataset Variant | Best Model | Paper | Code |
|---|---|---|---|---|---|

|
LibriSpeech test-clean
|
Conformer + Wav2vec 2.0 + SpecAugment-based Noisy Student Training with Libri-Light
|
|||

|
LibriSpeech test-other
|
parakeet-rnnt-1.1b
|
|||

|
Librispeech (clean)
|
hubert-large-ls960-ft
|
|||

|
Librispeech (other)
|
wav2vec2-large-960h-lv60
|
|||

|
LibriSpeech
|
CPC
|
|||

|
LibriSpeech test-clean
|
MonoBERT
|
|||

|
LibriSpeech test-other
|
MonoBERT
|
|||

|
LibriSpeech test-clean
|
kNN-VC
|
Papers
| Paper | Code | Results | Date | Stars |
|---|






