Atom: Low-bit Quantization for Efficient and Accurate LLM Serving
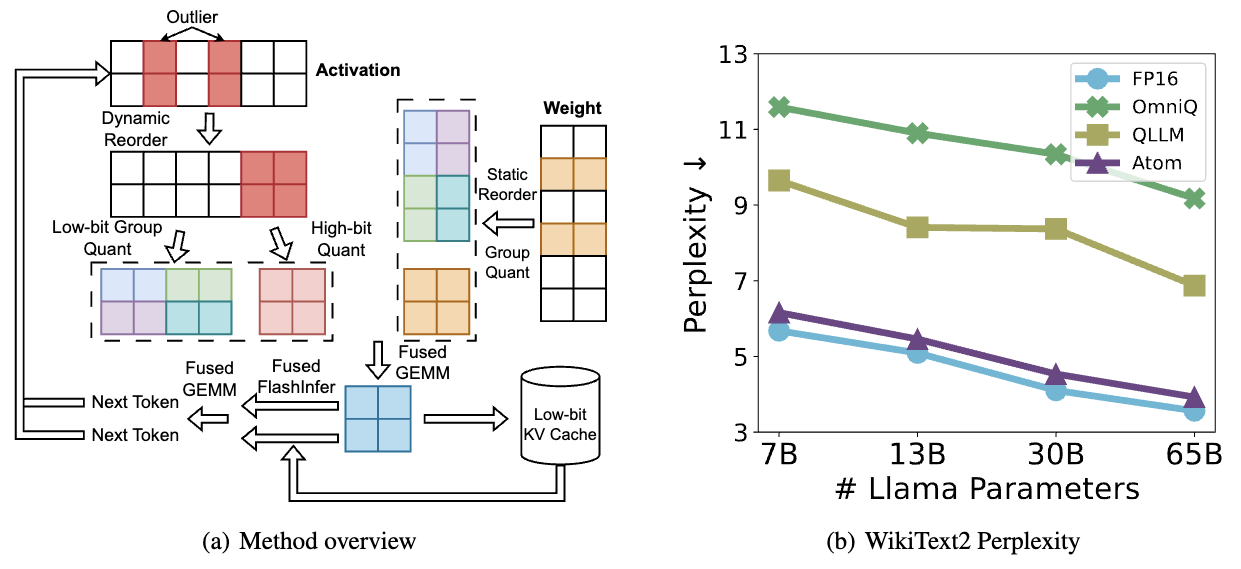
The growing demand for Large Language Models (LLMs) in applications such as content generation, intelligent chatbots, and sentiment analysis poses considerable challenges for LLM service providers. To efficiently use GPU resources and boost throughput, batching multiple requests has emerged as a popular paradigm; to further speed up batching, LLM quantization techniques reduce memory consumption and increase computing capacity. However, prevalent quantization schemes (e.g., 8-bit weight-activation quantization) cannot fully leverage the capabilities of modern GPUs, such as 4-bit integer operators, resulting in sub-optimal performance. To maximize LLMs' serving throughput, we introduce Atom, a low-bit quantization method that achieves high throughput improvements with negligible accuracy loss. Atom significantly boosts serving throughput by using low-bit operators and considerably reduces memory consumption via low-bit quantization. It attains high accuracy by applying a novel mixed-precision and fine-grained quantization process. We evaluate Atom on 4-bit weight-activation quantization in the serving context. Atom improves end-to-end throughput (token/s) by up to $7.7\times$ compared to the FP16 and by $2.5\times$ compared to INT8 quantization, while maintaining the same latency target.
PDF Abstract


 WikiText-2
WikiText-2
 C4
C4
 HellaSwag
HellaSwag
 BoolQ
BoolQ
 PIQA
PIQA
 WinoGrande
WinoGrande
