Automatic Data Augmentation for Generalization in Deep Reinforcement Learning
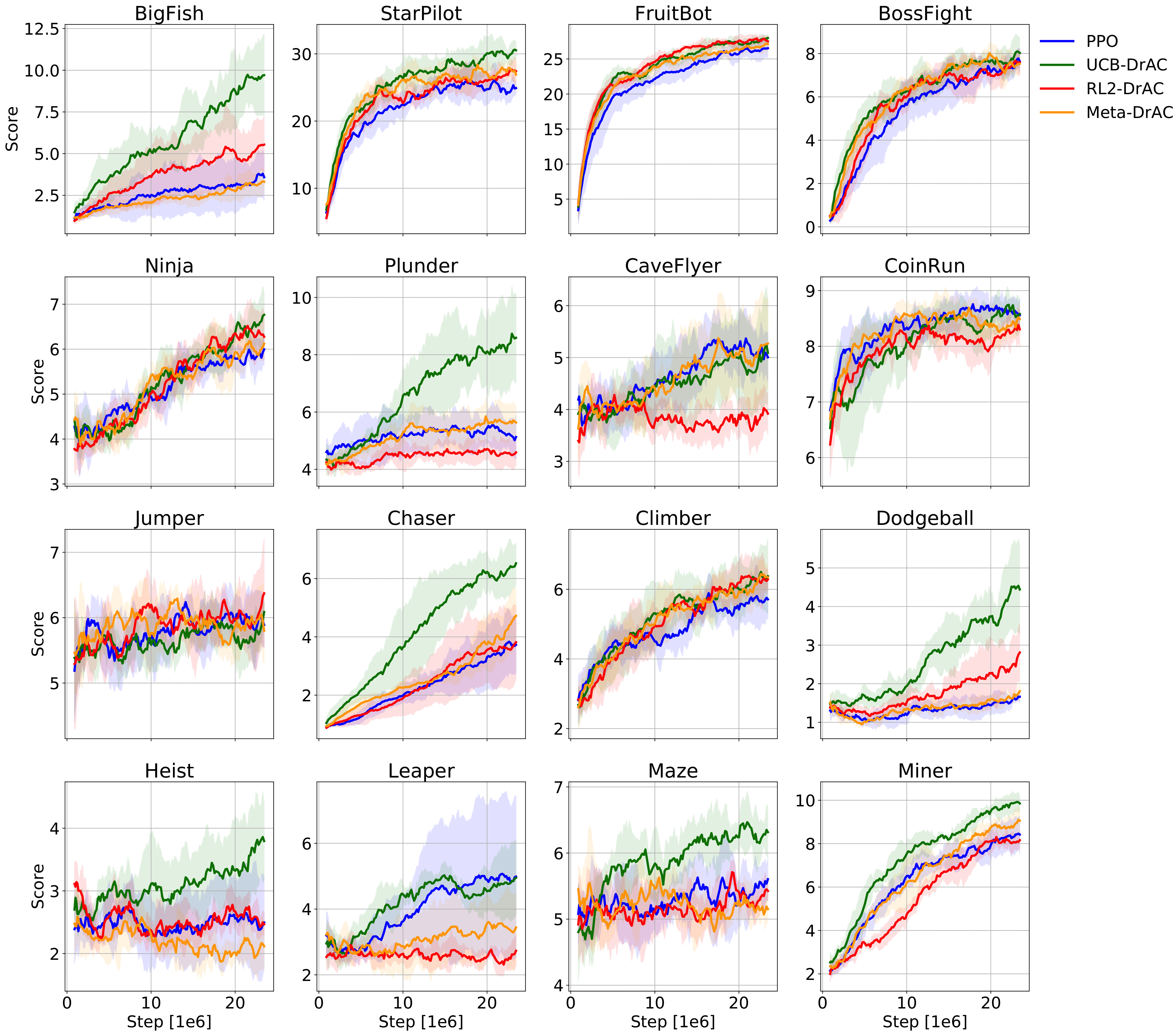
Deep reinforcement learning (RL) agents often fail to generalize to unseen scenarios, even when they are trained on many instances of semantically similar environments. Data augmentation has recently been shown to improve the sample efficiency and generalization of RL agents. However, different tasks tend to benefit from different kinds of data augmentation. In this paper, we compare three approaches for automatically finding an appropriate augmentation. These are combined with two novel regularization terms for the policy and value function, required to make the use of data augmentation theoretically sound for certain actor-critic algorithms. We evaluate our methods on the Procgen benchmark which consists of 16 procedurally-generated environments and show that it improves test performance by ~40% relative to standard RL algorithms. Our agent outperforms other baselines specifically designed to improve generalization in RL. In addition, we show that our agent learns policies and representations that are more robust to changes in the environment that do not affect the agent, such as the background. Our implementation is available at https://github.com/rraileanu/auto-drac.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract


 ProcGen
ProcGen
