Batch Normalization with Enhanced Linear Transformation
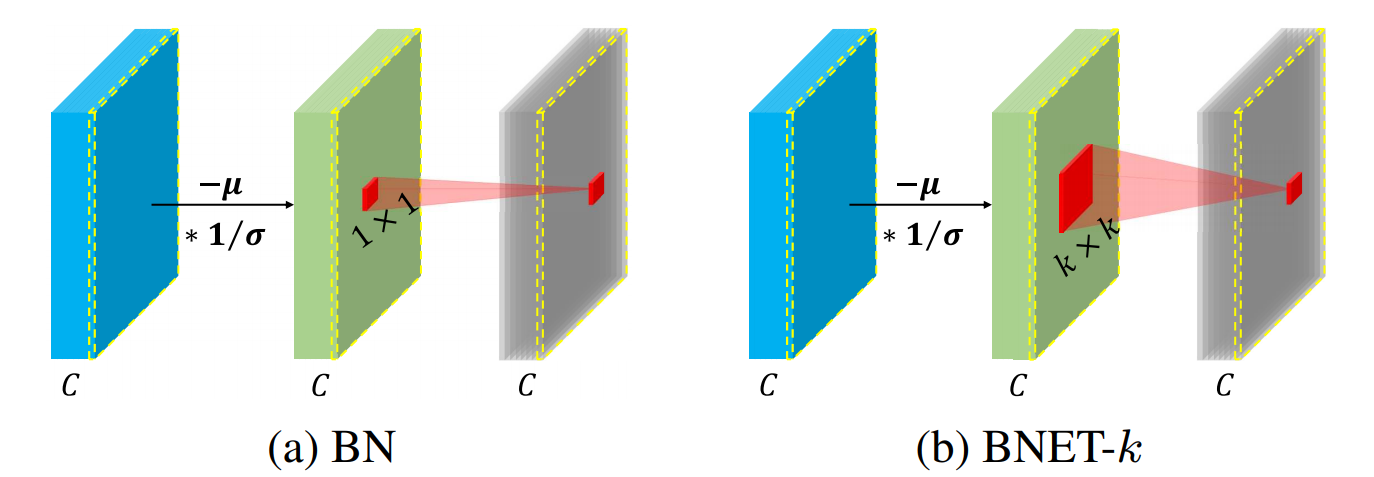
Batch normalization (BN) is a fundamental unit in modern deep networks, in which a linear transformation module was designed for improving BN's flexibility of fitting complex data distributions. In this paper, we demonstrate properly enhancing this linear transformation module can effectively improve the ability of BN. Specifically, rather than using a single neuron, we propose to additionally consider each neuron's neighborhood for calculating the outputs of the linear transformation. Our method, named BNET, can be implemented with 2-3 lines of code in most deep learning libraries. Despite the simplicity, BNET brings consistent performance gains over a wide range of backbones and visual benchmarks. Moreover, we verify that BNET accelerates the convergence of network training and enhances spatial information by assigning the important neurons with larger weights accordingly. The code is available at https://github.com/yuhuixu1993/BNET.
PDF Abstract
 ImageNet
ImageNet
 MS COCO
MS COCO
 Cityscapes
Cityscapes
 UCF101
UCF101
