Beyond Generation: Harnessing Text to Image Models for Object Detection and Segmentation
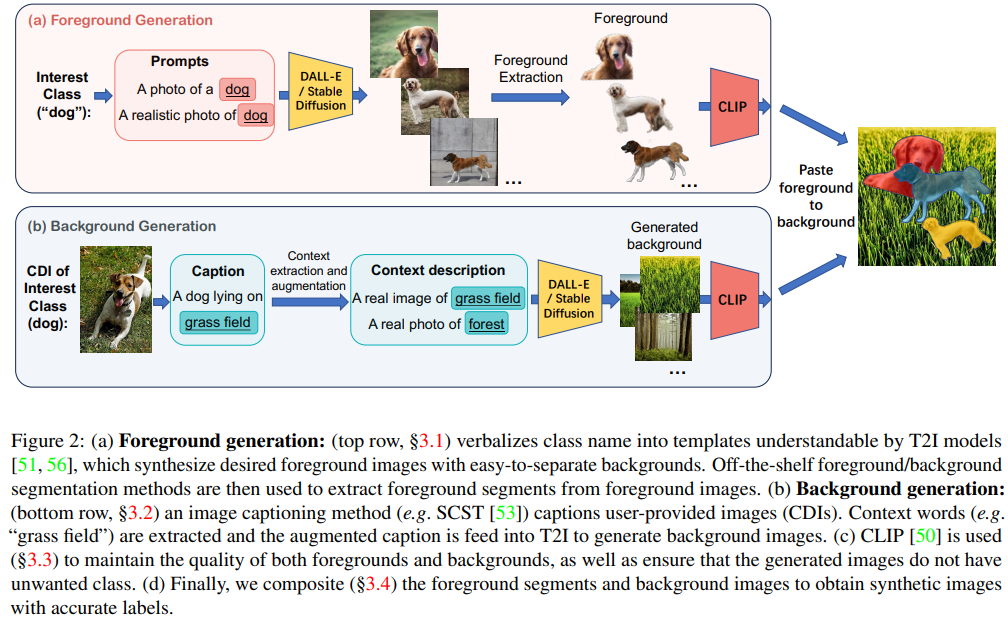
We propose a new paradigm to automatically generate training data with accurate labels at scale using the text-to-image synthesis frameworks (e.g., DALL-E, Stable Diffusion, etc.). The proposed approach1 decouples training data generation into foreground object generation, and contextually coherent background generation. To generate foreground objects, we employ a straightforward textual template, incorporating the object class name as input prompts. This is fed into a text-to-image synthesis framework, producing various foreground images set against isolated backgrounds. A foreground-background segmentation algorithm is then used to generate foreground object masks. To generate context images, we begin by creating language descriptions of the context. This is achieved by applying an image captioning method to a small set of images representing the desired context. These textual descriptions are then transformed into a diverse array of context images via a text-to-image synthesis framework. Subsequently, we composite these with the foreground object masks produced in the initial step, utilizing a cut-and-paste method, to formulate the training data. We demonstrate the advantages of our approach on five object detection and segmentation datasets, including Pascal VOC and COCO. We found that detectors trained solely on synthetic data produced by our method achieve performance comparable to those trained on real data (Fig. 1). Moreover, a combination of real and synthetic data yields even much better results. Further analysis indicates that the synthetic data distribution complements the real data distribution effectively. Additionally, we emphasize the compositional nature of our data generation approach in out-of-distribution and zero-shot data generation scenarios. We open-source our code at https://github.com/gyhandy/Text2Image-for-Detection
PDF Abstract




 MS COCO
MS COCO
 YCB-Video
YCB-Video
