Exploring Discontinuity for Video Frame Interpolation
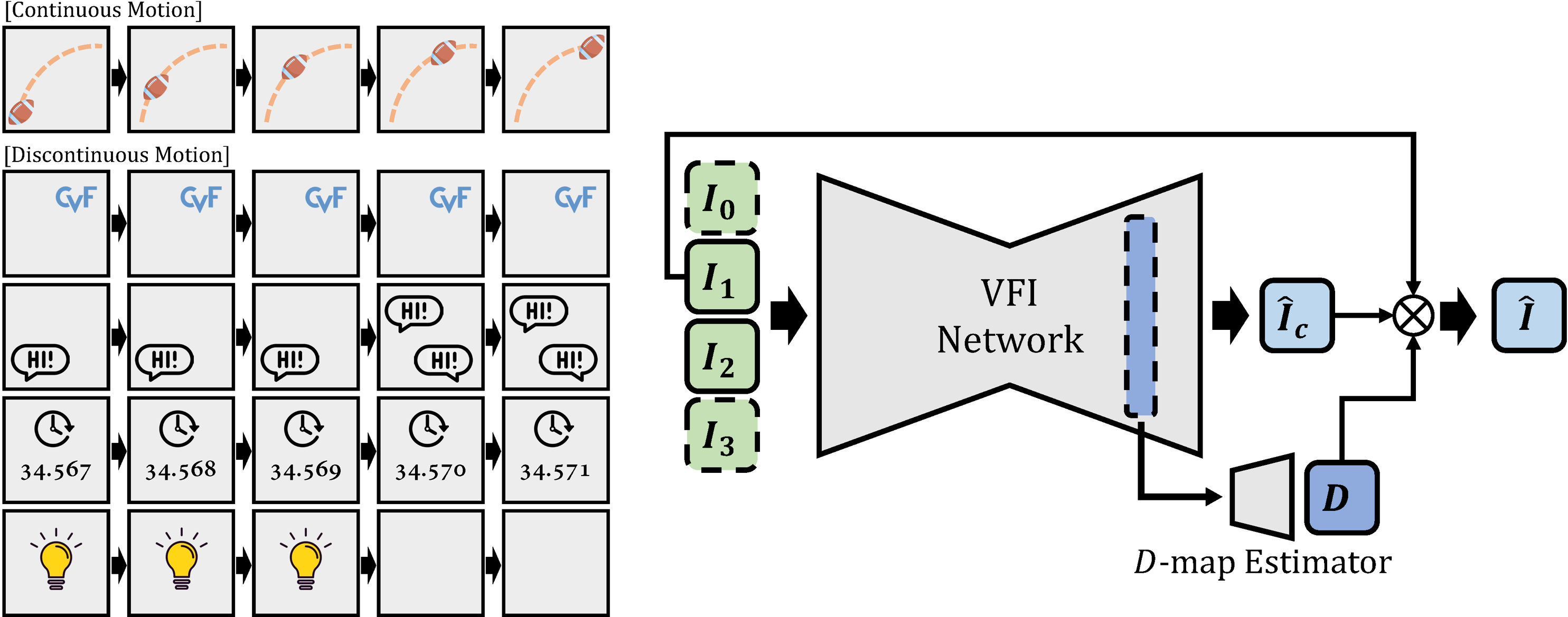
Video frame interpolation (VFI) is the task that synthesizes the intermediate frame given two consecutive frames. Most of the previous studies have focused on appropriate frame warping operations and refinement modules for the warped frames. These studies have been conducted on natural videos containing only continuous motions. However, many practical videos contain various unnatural objects with discontinuous motions such as logos, user interfaces and subtitles. We propose three techniques to make the existing deep learning-based VFI architectures robust to these elements. First is a novel data augmentation strategy called figure-text mixing (FTM) which can make the models learn discontinuous motions during training stage without any extra dataset. Second, we propose a simple but effective module that predicts a map called discontinuity map (D-map), which densely distinguishes between areas of continuous and discontinuous motions. Lastly, we propose loss functions to give supervisions of the discontinuous motion areas which can be applied along with FTM and D-map. We additionally collect a special test benchmark called Graphical Discontinuous Motion (GDM) dataset consisting of some mobile games and chatting videos. Applied to the various state-of-the-art VFI networks, our method significantly improves the interpolation qualities on the videos from not only GDM dataset, but also the existing benchmarks containing only continuous motions such as Vimeo90K, UCF101, and DAVIS.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract


 UCF101
UCF101
 DAVIS 2017
DAVIS 2017
