Boosting Crowd Counting via Multifaceted Attention
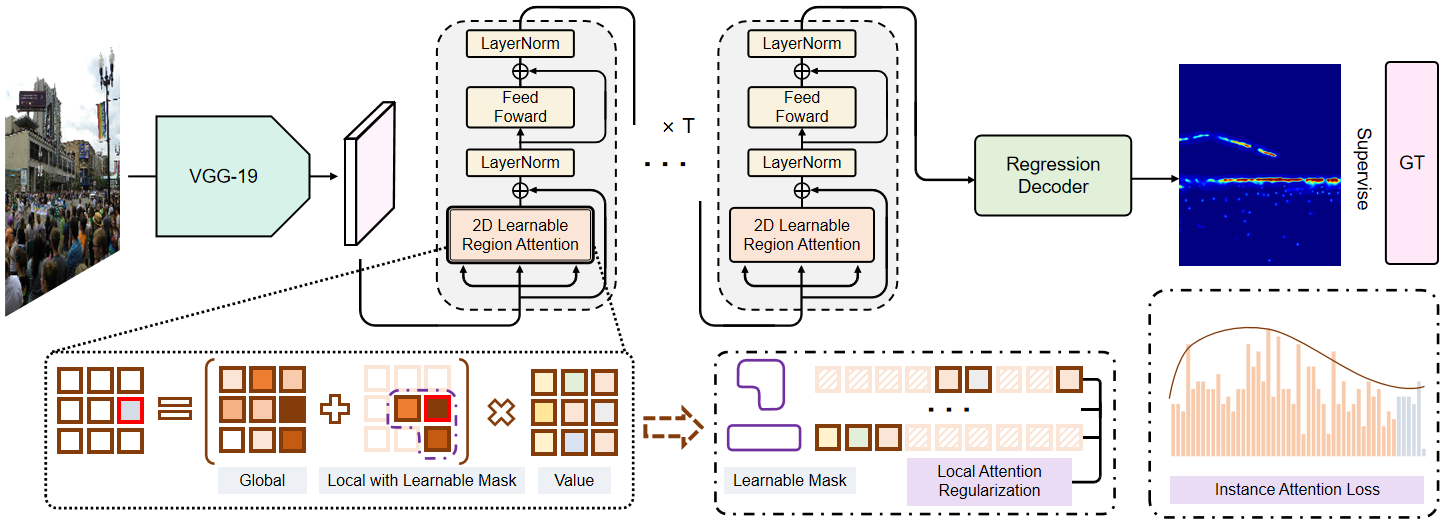
This paper focuses on the challenging crowd counting task. As large-scale variations often exist within crowd images, neither fixed-size convolution kernel of CNN nor fixed-size attention of recent vision transformers can well handle this kind of variation. To address this problem, we propose a Multifaceted Attention Network (MAN) to improve transformer models in local spatial relation encoding. MAN incorporates global attention from a vanilla transformer, learnable local attention, and instance attention into a counting model. Firstly, the local Learnable Region Attention (LRA) is proposed to assign attention exclusively for each feature location dynamically. Secondly, we design the Local Attention Regularization to supervise the training of LRA by minimizing the deviation among the attention for different feature locations. Finally, we provide an Instance Attention mechanism to focus on the most important instances dynamically during training. Extensive experiments on four challenging crowd counting datasets namely ShanghaiTech, UCF-QNRF, JHU++, and NWPU have validated the proposed method. Codes: https://github.com/LoraLinH/Boosting-Crowd-Counting-via-Multifaceted-Attention.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract

 ShanghaiTech
ShanghaiTech
 UCF-QNRF
UCF-QNRF
 JHU-CROWD++
JHU-CROWD++
