Class Feature Pyramids for Video Explanation
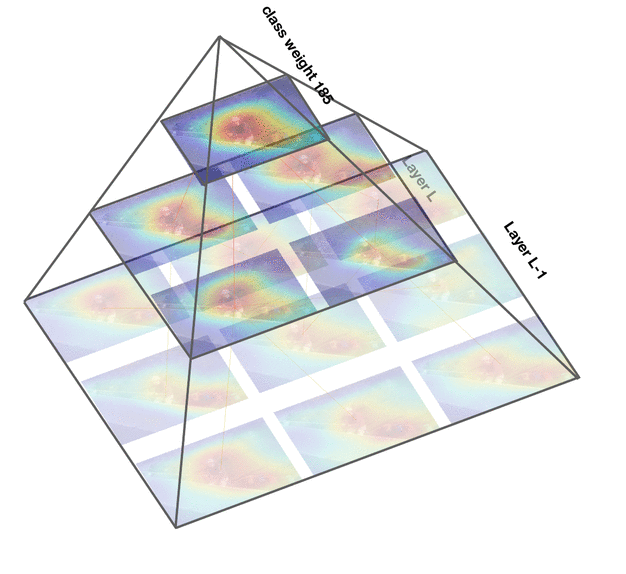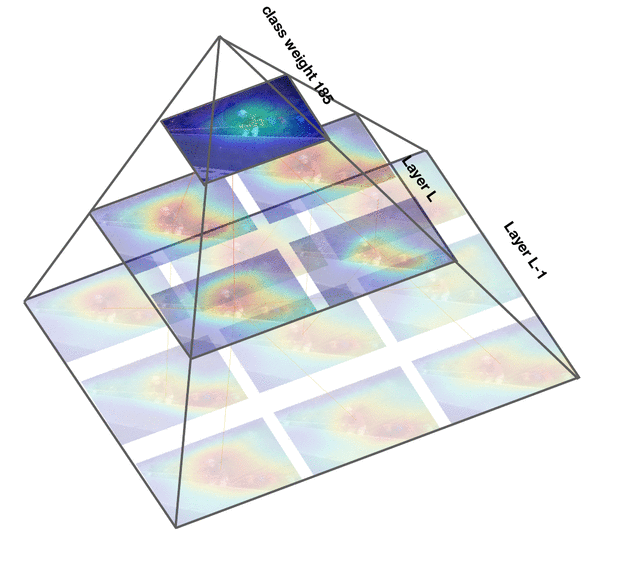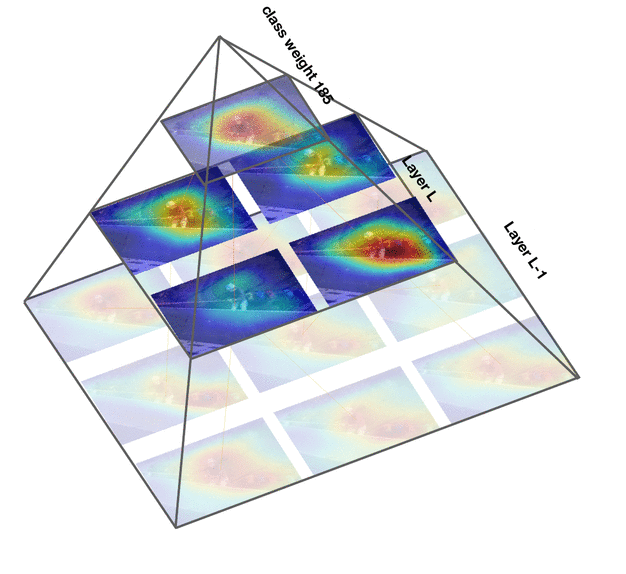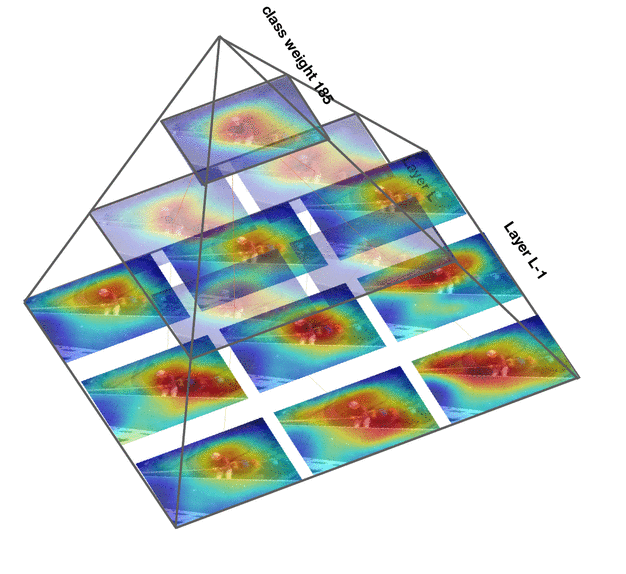
Deep convolutional networks are widely used in video action recognition. 3D convolutions are one prominent approach to deal with the additional time dimension. While 3D convolutions typically lead to higher accuracies, the inner workings of the trained models are more difficult to interpret. We focus on creating human-understandable visual explanations that represent the hierarchical parts of spatio-temporal networks. We introduce Class Feature Pyramids, a method that traverses the entire network structure and incrementally discovers kernels at different network depths that are informative for a specific class. Our method does not depend on the network's architecture or the type of 3D convolutions, supporting grouped and depth-wise convolutions, convolutions in fibers, and convolutions in branches. We demonstrate the method on six state-of-the-art 3D convolution neural networks (CNNs) on three action recognition (Kinetics-400, UCF-101, and HMDB-51) and two egocentric action recognition datasets (EPIC-Kitchens and EGTEA Gaze+).
PDF Abstract


 UCF101
UCF101
 HMDB51
HMDB51
 EGTEA
EGTEA
