CLIP Itself is a Strong Fine-tuner: Achieving 85.7% and 88.0% Top-1 Accuracy with ViT-B and ViT-L on ImageNet
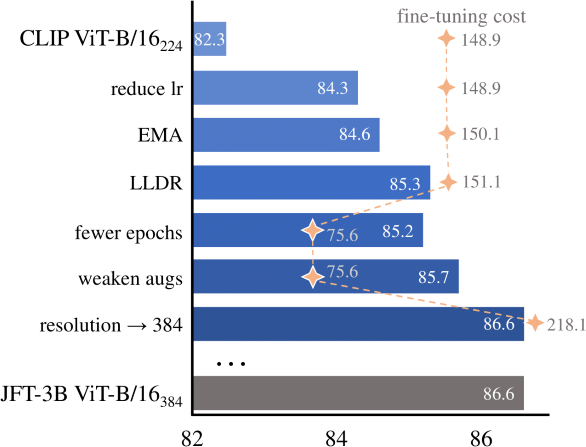
Recent studies have shown that CLIP has achieved remarkable success in performing zero-shot inference while its fine-tuning performance is not satisfactory. In this paper, we identify that fine-tuning performance is significantly impacted by hyper-parameter choices. We examine various key hyper-parameters and empirically evaluate their impact in fine-tuning CLIP for classification tasks through a comprehensive study. We find that the fine-tuning performance of CLIP is substantially underestimated. Equipped with hyper-parameter refinement, we demonstrate CLIP itself is better or at least competitive in fine-tuning compared with large-scale supervised pre-training approaches or latest works that use CLIP as prediction targets in Masked Image Modeling. Specifically, CLIP ViT-Base/16 and CLIP ViT-Large/14 can achieve 85.7%,88.0% finetuning Top-1 accuracy on the ImageNet-1K dataset . These observations challenge the conventional conclusion that CLIP is not suitable for fine-tuning, and motivate us to rethink recently proposed improvements based on CLIP. We will release our code publicly at \url{https://github.com/LightDXY/FT-CLIP}.
PDF Abstract
