Conditional Directed Graph Convolution for 3D Human Pose Estimation
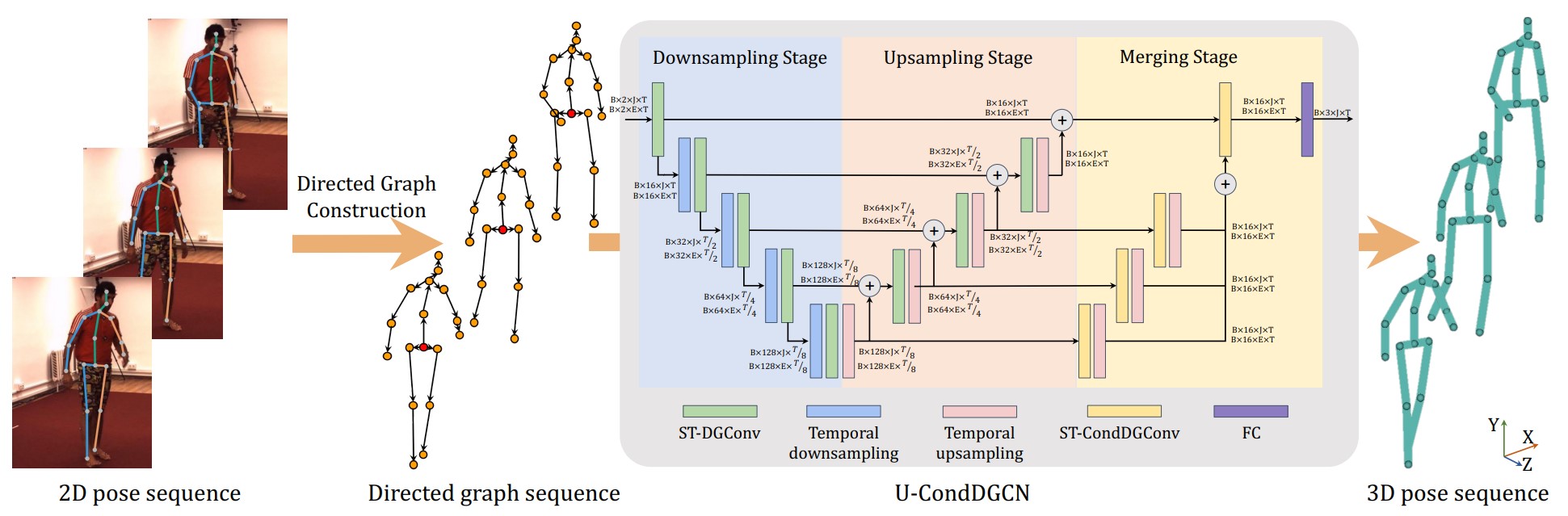
Graph convolutional networks have significantly improved 3D human pose estimation by representing the human skeleton as an undirected graph. However, this representation fails to reflect the articulated characteristic of human skeletons as the hierarchical orders among the joints are not explicitly presented. In this paper, we propose to represent the human skeleton as a directed graph with the joints as nodes and bones as edges that are directed from parent joints to child joints. By so doing, the directions of edges can explicitly reflect the hierarchical relationships among the nodes. Based on this representation, we further propose a spatial-temporal conditional directed graph convolution to leverage varying non-local dependence for different poses by conditioning the graph topology on input poses. Altogether, we form a U-shaped network, named U-shaped Conditional Directed Graph Convolutional Network, for 3D human pose estimation from monocular videos. To evaluate the effectiveness of our method, we conducted extensive experiments on two challenging large-scale benchmarks: Human3.6M and MPI-INF-3DHP. Both quantitative and qualitative results show that our method achieves top performance. Also, ablation studies show that directed graphs can better exploit the hierarchy of articulated human skeletons than undirected graphs, and the conditional connections can yield adaptive graph topologies for different poses.
PDF Abstract


 Human3.6M
Human3.6M
 MPI-INF-3DHP
MPI-INF-3DHP

