Conditional Variational Autoencoder for Sign Language Translation with Cross-Modal Alignment
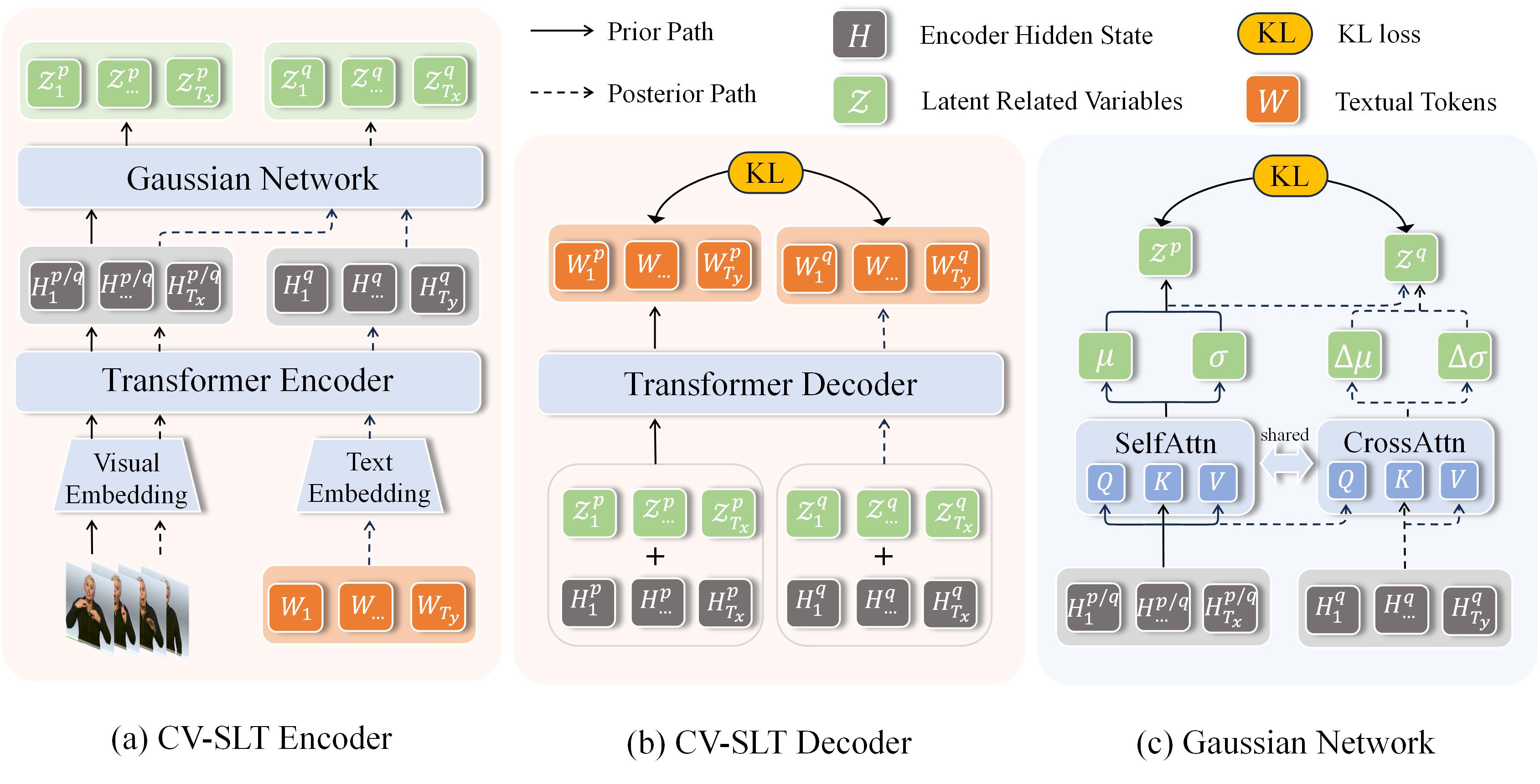
Sign language translation (SLT) aims to convert continuous sign language videos into textual sentences. As a typical multi-modal task, there exists an inherent modality gap between sign language videos and spoken language text, which makes the cross-modal alignment between visual and textual modalities crucial. However, previous studies tend to rely on an intermediate sign gloss representation to help alleviate the cross-modal problem thereby neglecting the alignment across modalities that may lead to compromised results. To address this issue, we propose a novel framework based on Conditional Variational autoencoder for SLT (CV-SLT) that facilitates direct and sufficient cross-modal alignment between sign language videos and spoken language text. Specifically, our CV-SLT consists of two paths with two Kullback-Leibler (KL) divergences to regularize the outputs of the encoder and decoder, respectively. In the prior path, the model solely relies on visual information to predict the target text; whereas in the posterior path, it simultaneously encodes visual information and textual knowledge to reconstruct the target text. The first KL divergence optimizes the conditional variational autoencoder and regularizes the encoder outputs, while the second KL divergence performs a self-distillation from the posterior path to the prior path, ensuring the consistency of decoder outputs. We further enhance the integration of textual information to the posterior path by employing a shared Attention Residual Gaussian Distribution (ARGD), which considers the textual information in the posterior path as a residual component relative to the prior path. Extensive experiments conducted on public datasets (PHOENIX14T and CSL-daily) demonstrate the effectiveness of our framework, achieving new state-of-the-art results while significantly alleviating the cross-modal representation discrepancy.
PDF Abstract


