Contextualize, Show and Tell: A Neural Visual Storyteller
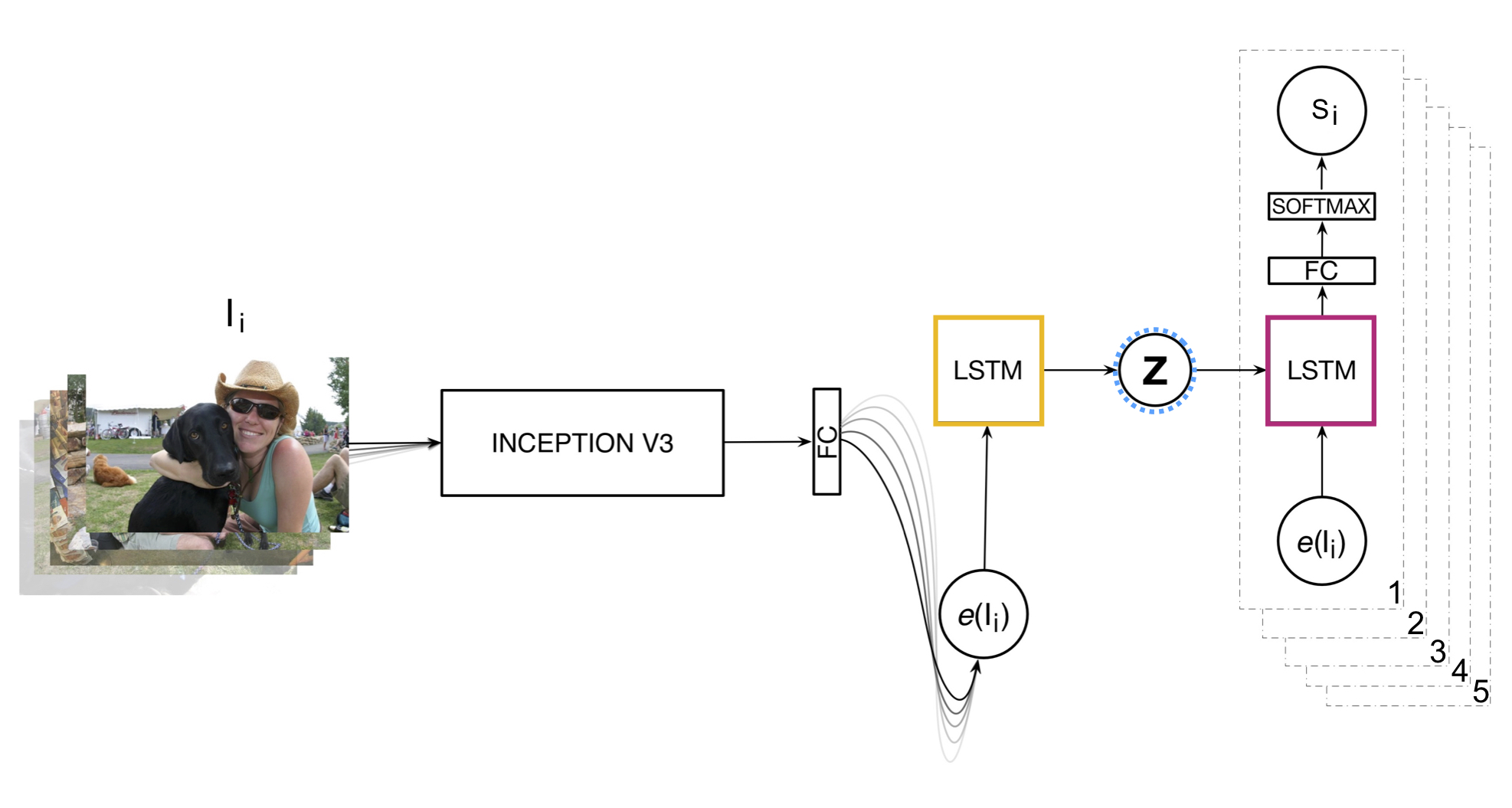
We present a neural model for generating short stories from image sequences, which extends the image description model by Vinyals et al. (Vinyals et al., 2015). This extension relies on an encoder LSTM to compute a context vector of each story from the image sequence. This context vector is used as the first state of multiple independent decoder LSTMs, each of which generates the portion of the story corresponding to each image in the sequence by taking the image embedding as the first input. Our model showed competitive results with the METEOR metric and human ratings in the internal track of the Visual Storytelling Challenge 2018.
PDF Abstract

 VIST
VIST

