Self-supervised Spatial Reasoning on Multi-View Line Drawings
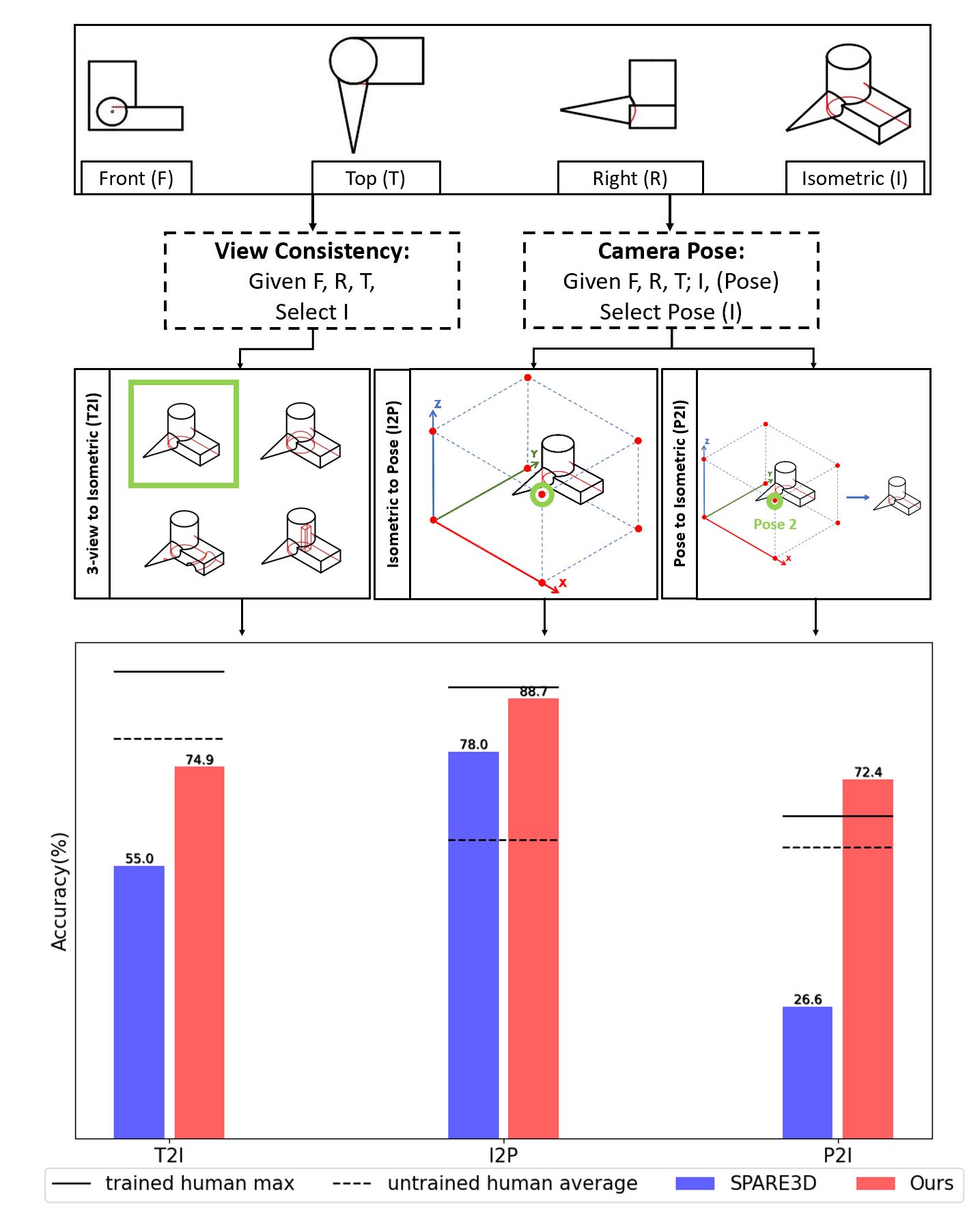
Spatial reasoning on multi-view line drawings by state-of-the-art supervised deep networks is recently shown with puzzling low performances on the SPARE3D dataset. Based on the fact that self-supervised learning is helpful when a large number of data are available, we propose two self-supervised learning approaches to improve the baseline performance for view consistency reasoning and camera pose reasoning tasks on the SPARE3D dataset. For the first task, we use a self-supervised binary classification network to contrast the line drawing differences between various views of any two similar 3D objects, enabling the trained networks to effectively learn detail-sensitive yet view-invariant line drawing representations of 3D objects. For the second type of task, we propose a self-supervised multi-class classification framework to train a model to select the correct corresponding view from which a line drawing is rendered. Our method is even helpful for the downstream tasks with unseen camera poses. Experiments show that our method could significantly increase the baseline performance in SPARE3D, while some popular self-supervised learning methods cannot.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract



 ImageNet
ImageNet
