Crafting Monocular Cues and Velocity Guidance for Self-Supervised Multi-Frame Depth Learning
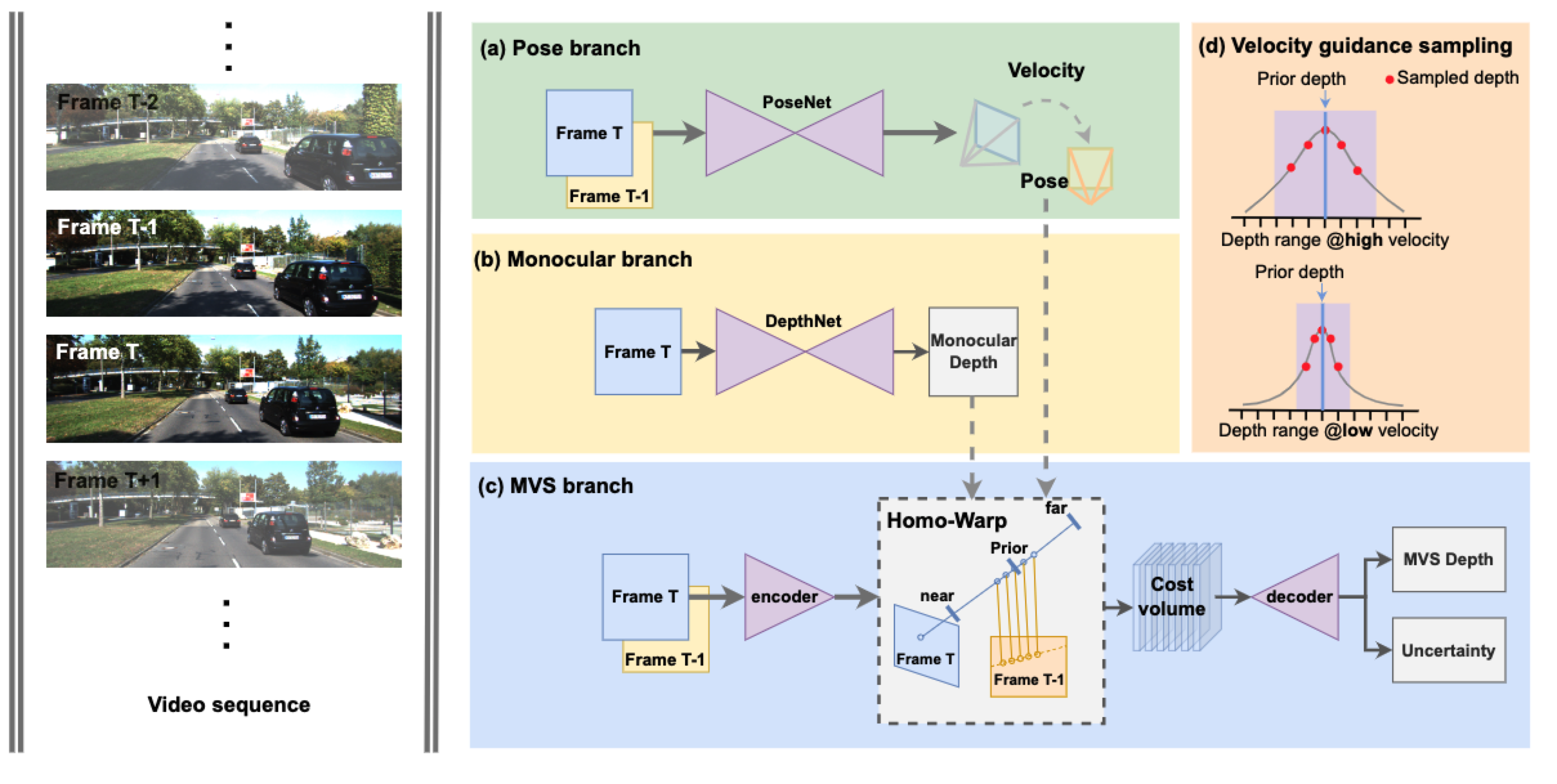
Self-supervised monocular methods can efficiently learn depth information of weakly textured surfaces or reflective objects. However, the depth accuracy is limited due to the inherent ambiguity in monocular geometric modeling. In contrast, multi-frame depth estimation methods improve the depth accuracy thanks to the success of Multi-View Stereo (MVS), which directly makes use of geometric constraints. Unfortunately, MVS often suffers from texture-less regions, non-Lambertian surfaces, and moving objects, especially in real-world video sequences without known camera motion and depth supervision. Therefore, we propose MOVEDepth, which exploits the MOnocular cues and VElocity guidance to improve multi-frame Depth learning. Unlike existing methods that enforce consistency between MVS depth and monocular depth, MOVEDepth boosts multi-frame depth learning by directly addressing the inherent problems of MVS. The key of our approach is to utilize monocular depth as a geometric priority to construct MVS cost volume, and adjust depth candidates of cost volume under the guidance of predicted camera velocity. We further fuse monocular depth and MVS depth by learning uncertainty in the cost volume, which results in a robust depth estimation against ambiguity in multi-view geometry. Extensive experiments show MOVEDepth achieves state-of-the-art performance: Compared with Monodepth2 and PackNet, our method relatively improves the depth accuracy by 20\% and 19.8\% on the KITTI benchmark. MOVEDepth also generalizes to the more challenging DDAD benchmark, relatively outperforming ManyDepth by 7.2\%. The code is available at https://github.com/JeffWang987/MOVEDepth.
PDF Abstract

 KITTI
KITTI
 DDAD
DDAD
