Cross-Lingual Machine Reading Comprehension
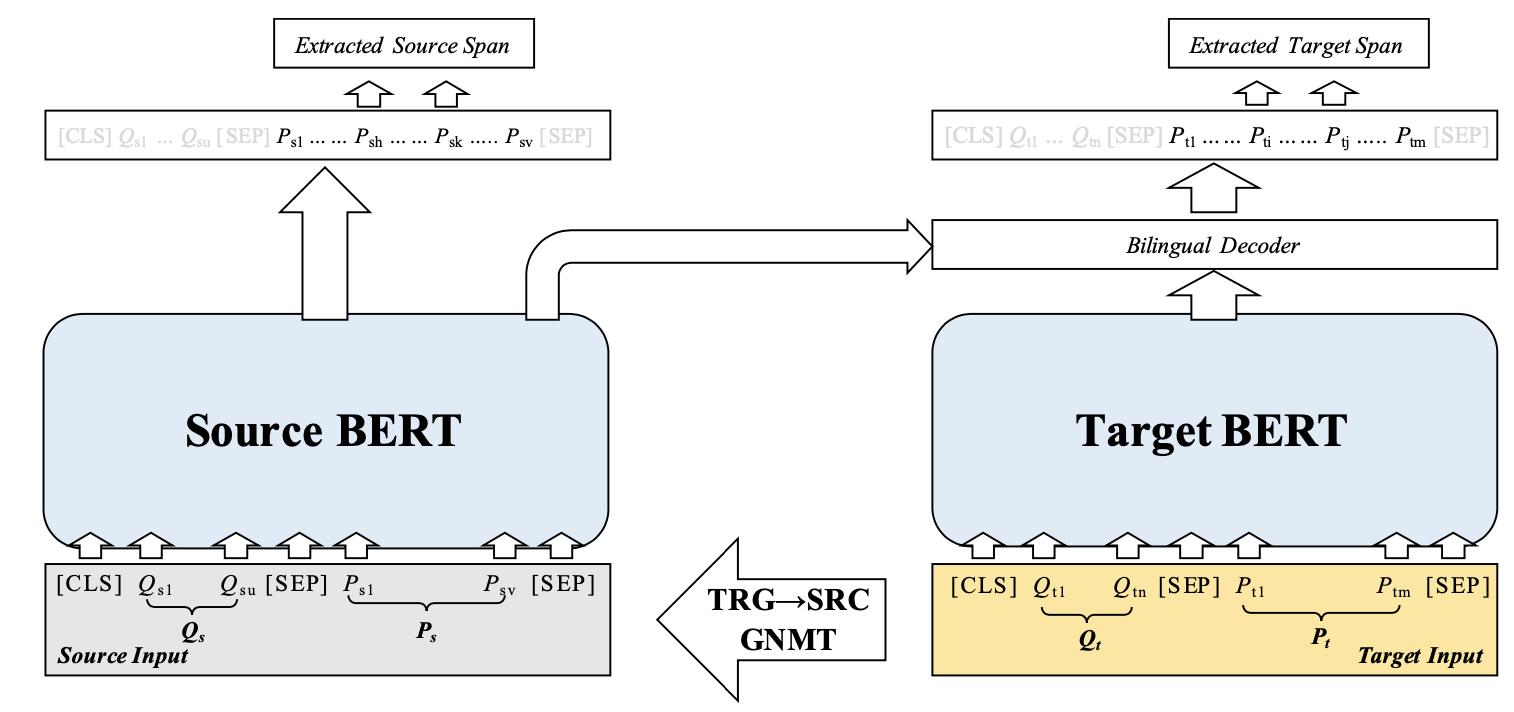
Though the community has made great progress on Machine Reading Comprehension (MRC) task, most of the previous works are solving English-based MRC problems, and there are few efforts on other languages mainly due to the lack of large-scale training data. In this paper, we propose Cross-Lingual Machine Reading Comprehension (CLMRC) task for the languages other than English. Firstly, we present several back-translation approaches for CLMRC task, which is straightforward to adopt. However, to accurately align the answer into another language is difficult and could introduce additional noise. In this context, we propose a novel model called Dual BERT, which takes advantage of the large-scale training data provided by rich-resource language (such as English) and learn the semantic relations between the passage and question in a bilingual context, and then utilize the learned knowledge to improve reading comprehension performance of low-resource language. We conduct experiments on two Chinese machine reading comprehension datasets CMRC 2018 and DRCD. The results show consistent and significant improvements over various state-of-the-art systems by a large margin, which demonstrate the potentials in CLMRC task. Resources available: https://github.com/ymcui/Cross-Lingual-MRC
PDF Abstract IJCNLP 2019 PDF IJCNLP 2019 Abstract


 SQuAD
SQuAD
 CMRC
CMRC
 DRCD
DRCD

